Data Industry Primer

Welcome back to the Public Comps blog! Our goal is to provide high-quality, data-driven research on companies and industries. I also publish my research and other learnings regularly here.
My goal of this article is threefold:
- Provide an overview of the modern data landscape.
- Provide an understanding of where popular data companies fit into that landscape.
- Provide a starting point for readers to dive deeper into investment opportunities they find most interesting.
I’d like to make an important disclaimer. The data industry is incredibly fragmented. There are 1000s of data companies competing in hundreds of data niches. Additionally, I’m not a data specialist; just an investor studying the space. I will certainly miss important companies and important niches. However, my goal for this article is to be a simplifier of the space, not an all-encompassing deep dive into the industry.
For the sake of simplicity, I’m structuring this article in three phases: the history of data platforms, what a modern data platform looks like, and important companies (primarily public) in the data ecosystem.
A note on how I utilize this primer: I use it as an introduction to the space, to understand the major technologies, the major players, and their position in the ecosystem. Then, I dive deeper into companies based on the potential for my specific investment methodology. I encourage you to use it similarly.
I’ll start by sharing this image simplifying the industry, it’s explained further later.
History of Data Platforms
Like many of modern technology’s origins, the enterprise data management space starts in an IBM research lab. In 1970, an IBM researcher theorized a relational model for data banks. IBM created the first relational database management system (RDBMS) in 1974, and first sold it commercially in 1976 as a Multics Relational Data Store. The core product offered two features: data in a collection of tables and the ability to manipulate the data.
The IBM system went on to become SQL, DB2, and Oracle. Oracle was developed in 1979 with the CIA as their first major customer. Over time, they continued to evolve the oracle data ecosystem until it became the largest database management company in the world. In the 80s, SQL became the standard language for the data industry; that remains true to this day.
RDBMSs weren’t well suited for reporting and analytics, so the data warehouse was invented (by IBM researchers) in the late 80s. The data warehouse was designed to facilitate business analytics to make use of the growing amounts of data. On-prem data warehouses would quickly exceed their storage capacity, meaning customers had to continue to invest in data center capacity. This led to data warehouses being an expensive proposition.
In the 90s, the data industry saw a period of consolidation to the point where IBM, Oracle, and Microsoft were the three major players. Systems were complex, on-prem, and expensive.
The birth of the cloud
The internet and the cloud re-invigorated the industry. In 2006, AWS was launched.
The cloud offered the opportunity for small companies to make use of data warehouses and big data analytics. This opened the door for tech startups to start developing services without having to build expensive data centers. This ultimately led to the thousands of SaaS companies and data products on the market today.
Around the same time, NoSQL systems, database management tools that accepted unstructured data, were invented. MongoDB was founded in 2007.
With the rapid rise of data, Hadoop emerged as the first open source big data processing tool. For the first time, many companies could analyze huge amounts of unstructured data. This led to the advent of the data lake, a repository to store vast amounts of data, traditionally on Amazon S3 buckets.
However, Hadoop was complex, had limited security, and didn’t support streaming. This led to the development of Apache Spark in 2009. Spark was easier to use and supported functionality such as data streaming. The inventors of Apache Spark went on to found Databricks in 2013.
In 2012, Snowflake was launched. Snowflake marked an important change in data warehousing which was the separation of compute and storage. Compute refers to the computing power needed to transform and organize data. Storage refers to the actual storing of the data. This led to significant cost and performance savings for organizations.
Snowflake and Databricks would go on to become two of the defining data companies of the cloud era.
Ultimately, companies needed the computing power of a data warehouse, the flexibility of NoSQL, and the elasticity of the cloud.
Ergo, the modern cloud data ecosystem was born.
The Modern Data Ecosystem
The modern data ecosystem centers around cloud-based data warehouses, big data processing, and flexible storage systems such as NoSQL. Then, services such as observability, security, business intelligence, and increasingly AI workloads create the ecosystem around the core storage and compute functionality.
The modern data estate is heavily fragmented. Companies will use many tools to ingest, transform, store, visualize, secure, and govern data.
A popular vision for a modern data repository is the data lakehouse, an architecture that integrates the best features of the data lake and the data warehouse. Snowflake and Databricks are attempting to achieve this vision.
There are several emerging data architectures that have come to life in recent years. They all work in pursuit of the same vision for the RDBMS all those years ago: a unified data store to enable automated decision-making.
With that, let’s dive into the modern data ecosystem.
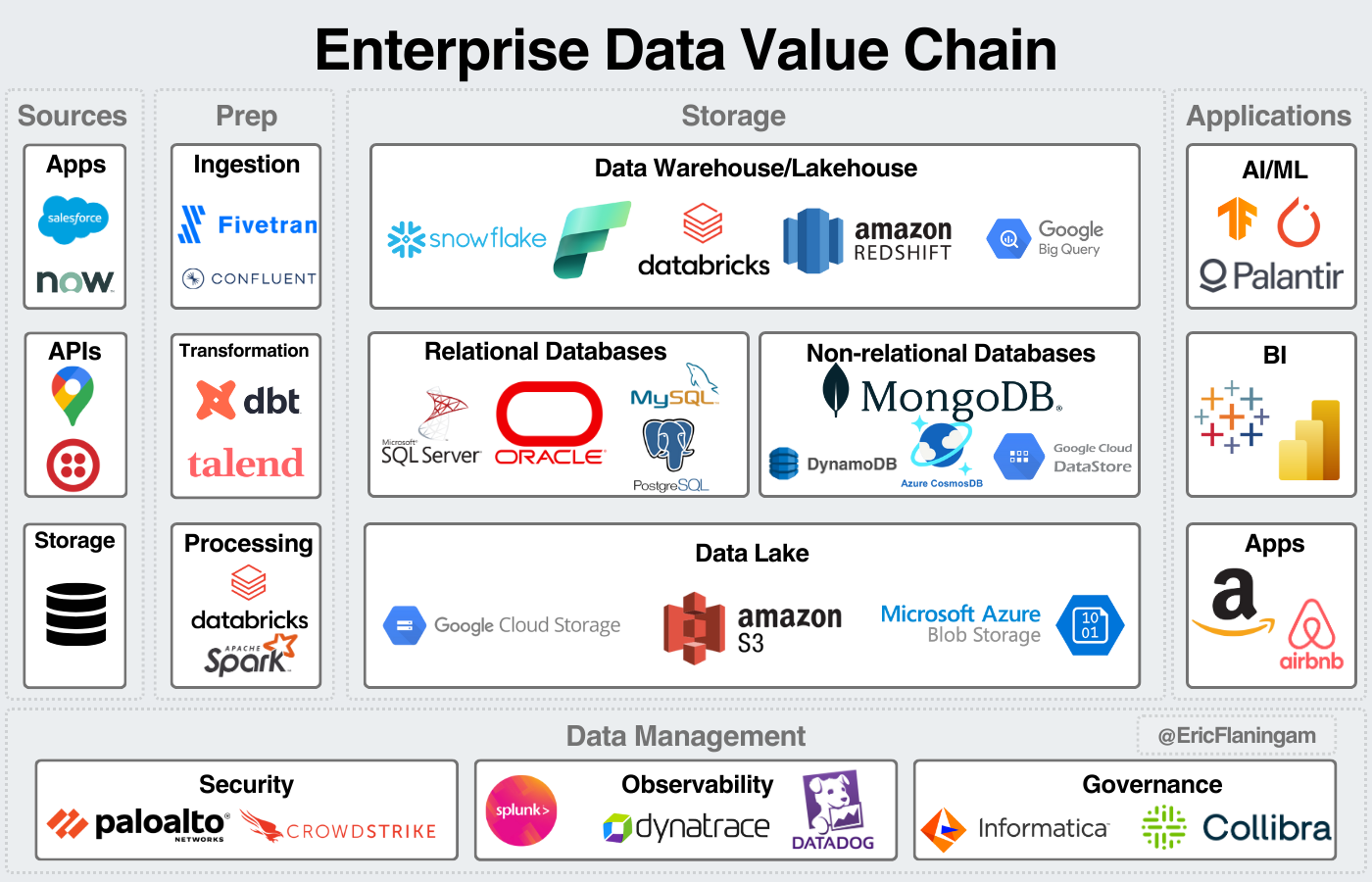
Data Ecosystem
I want to preface by saying the fragmentation of the industry makes simplifying the space into a simple graphic challenging. For example, data integration and orchestration were left out but are important pieces of the industry. In my opinion, these concessions are necessary to properly simplify the industry. For a comprehensive view of the industry, check out Matt Turck’s landscape.
The other important disclaimer is the blurred lines between these segments. Ingestion and processing blend together. Integration goes on throughout the data process. Security, observability, and governance all work together for data management. Data storage is becoming increasingly blurred between data lakes, warehouses, and databases.
Finally, many of these companies complete many steps in the process. For example, Snowflake and Databricks both offer services across Prep, Storage, Data Management, and Applications. Datadog offers security, observability, and governance. This image is meant to simplify the industry, it’s not an all-encompassing view of the companies in each step.
This image is meant to be a mental model to visualize the industry. There’s room for flexibility with that mental model.
1. An intro to data
Today, data can be measured and sourced in a wide variety of formats. At its core, data is stored as 1s and 0s. At the semiconductor level, this is how memory works. Each transistor is represented as a 1 or 0. One level higher, data can be stored as an integer, a floating point, a character, a string, an array, or date/time. There are a few others, but these are the major types of data.
At its core, all structured data comes down to these formats. Structured data, such as a SQL database has predefined data types. For example, a column will be predefined as an integer. Only integer data types can be stored in these columns.
Unstructured data is data stored without a predefined structure. This includes text, BLOB data such as images or videos, raw data in binary form, or XML which is a language to represent unstructured data. Unstructured data represents 80-90% of data generated and that number is growing. Finally, semi-structured data does not have a predefined data model but has some rules for defining data objects and arrays. JSON is the most common semi-structured data format.
2. Sources & Prep
Because of the wide array of data generated, sources are varied as well. Common data sources include enterprise apps, excel sheets, SQL databases, webpages, APIs, and IoT sensors. That data then needs to be imported into storage.
Ingestion is the first step in the process, where data from various sources can be imported into a data platform. There are two types of ingestion: batch and streaming. Batch periodically collects data and loads it into storage. Streaming is real-time processing, loading data as soon as it's created. Popular tools include Confluent, Apache Kafka, Fivetran, and StreamSets.
Processing then occurs, which includes the transformation of data into storage formats. Dbt is a popular tool for transformation. Databricks can do both ingestion and processing and is specialized for big data processing.
This brings up an important concept of ETL (extract-transform-load) vs ELT (extract-load-transform). Traditionally, to save money, companies would transform data (compute) and then load it into a data warehouse (storage). Now, cloud-based data warehouses and lakes separate storage and compute so transforming can cost-effectively be done within the storage layer. ELT gives data engineers the freedom to develop transformations according to their particular needs.
Finally, I’m including data integration into the Prep category although it really is done throughout the lifecycle.
Integration is the process of combining data into a unified format. This can include transformation as well. Orchestration includes a wide array of tools surrounding the process of scheduling, managing, and monitoring the flow of data. Data pipelines are a sub-segment of orchestration. Pipelines define how data is transferred between sources and can involve ingestion, transformation, and analysis.
I hope you see how complicated defining terms in this section can be. Different terms are used to define the same process with subtle differences.
The important part to understand is that data has to be organized and transformed before being stored and analyzed.
3. Storage
Storage is at the center of the modern data estate. Most of the companies in the limelight: Snowflake, MongoDB, Databricks, Azure, AWS, and GCP make this a pillar of their data strategy and then have an ecosystem around it.
After processing, the flow of data depends on the specific company’s architecture. A popular architecture is to store all data in a data lake. This is a store of unorganized data, most likely in cloud storage from AWS, Azure, or GCP. Then, data is transformed and added to specific databases, typically used for transactional work. Finally, all of those databases are managed in a data warehouse, typically used for making business intelligence more efficient.
Data Warehouse/Lakehouse:
The data warehouse is the center of the modern data estate. Consider it the central repository for data management. Raw data is transformed to a form that can be organized in the data warehouse. Then, data is pulled from the data warehouse to be used in AI/ML workflows, business intelligence, and customer-facing applications such as websites.
Data warehouses can be on-prem or in the cloud. The cloud-based data warehousing is one of the hottest markets in the world. There are five main players: Snowflake, Databricks, Google BigQuery, Amazon Redshift, and Microsoft Synapse* (Synapse is Microsoft’s data warehouse, but Microsoft is moving towards Fabric as their primary offering).
Traditionally, a data lake stores all types of data while a data warehouse only stores structured data. However, those lines are becoming blurred as data warehouses are offering support for unstructured data. This has led to the data lakehouse, heavily marketed by Databricks.
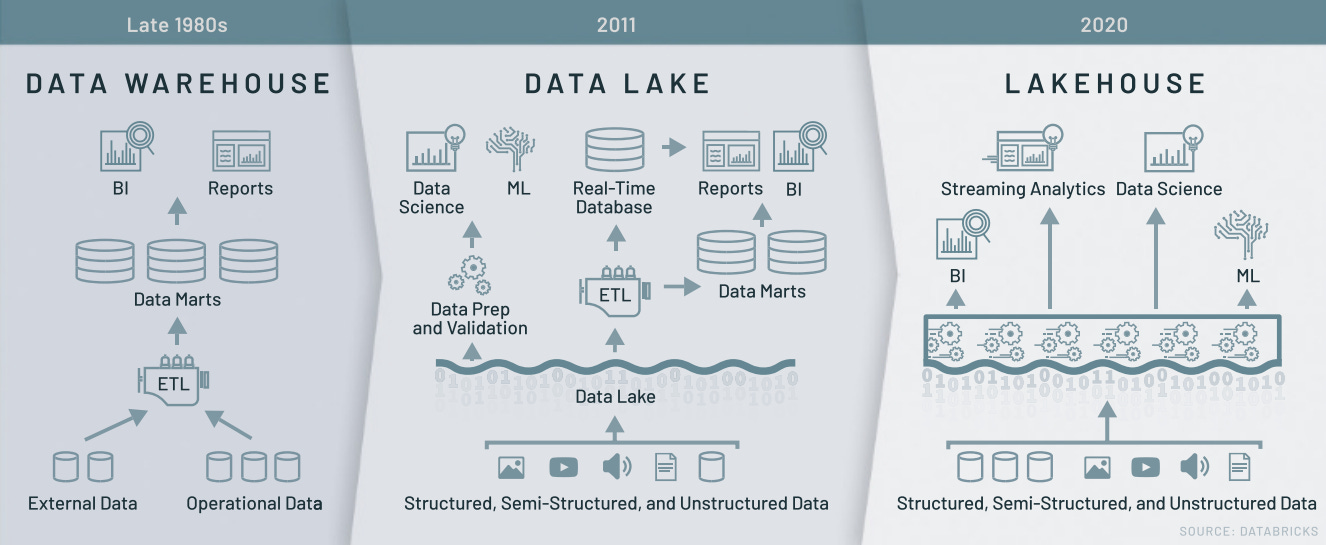
The vision for the lakehouse is to remove the need for databases and data warehouses. You can “simply” store your data in a data lake and cut out many of the unnecessary intermediary steps. Few enterprises, if any, have been able to achieve this vision.
Relational databases:
A relational database, or a SQL database, is the most common type of database. It is a collection of tables, with structured data, that are related by common variables.
Oracle is the largest relational database management systems (RDBMS) in the world. That’s followed by MySQL, Microsoft SQL Server, and PostgreSQL (an open-source alternative).
Non-relational databases:
Alternatively, a non-relational database, or NoSQL database, is one where the data is not related.
NoSQL databases mostly store unstructured data, such as sensor data, web logs, media, audio, etc.
There are four main types of NoSQL databases: key-value, document, wide-column, and graph databases.
The most popular is MongoDB, which is a document database. Data is stored in JSON files (semi-structured), with two variables: a key and a value.
Data Lake:
As mentioned earlier, a data lake is the store of all data for a company. This is typically unstructured data, and it’s stored in cloud object storage. The most common of which is Amazon S3, simple storage service. Microsoft has BLOB storage, and GCP has Google Cloud Storage.
The vision is for the data lake to be the only source of data you need; however, I’m skeptical of this vision in the near future.
4. Applications
In this section, I consider applications to be any use case for data. I’m not going to spend much time on this, because each use case could be its section.
AI/ML is the most popular use case right now. I think this diagram visualizes the AI data flow well. AI models continuously interact with data stores in both data lakes and data warehouses.
The image also shows business intelligence which typically pulls directly from data warehouses as they were originally designed to facilitate BI workloads.
You can then visualize how data flows to websites, business apps, applications, and any other endpoint for data.
5. Data Management
Data management may be a poor title for this section, but I’m including security, observability, and governance in this section. These tools are absolutely critical for enterprises. They are also HIGHLY challenging to develop. Few really good governance tools exist because of how challenging the task is.
Here’s why it’s so challenging:
Enterprises have data stored in SQL databases, NoSQL databases, data lakes, data warehouses, applications, excel sheets, emails, word docs. Those can be on-prem or on the cloud, often both. Then, they continuously have data coming in from a variety of sources. That data is stored in different formats and in different systems that could be anywhere from a year old to 20 years old.
It’s so challenging to develop a tool that can track and manage what all that data means.
Because it’s such an important challenge for companies, it’s also lucrative for the big data providers which is why they’re all developing security and governance tools.
Data Management
Security, observability, and governance are tightly linked so I’m going to include them in one section. The overall goal is to ensure that organizations know what data they have, who has access to that data, and that data is secure from cyberattacks. Each of the three tools works closely together to achieve these goals.
Observability is the process of monitoring and measuring the health, reliability, and security of data systems. Datadog, Dynatrace, and New Relic are three of the largest observability providers. Governance is the process of managing data to ensure the security and compliance of data. It involves setting policies for storage and access of data. Security is the process of securing data in an organization. It includes antivirus, firewall, encryption, VPN, identity and access management, key management. Large providers include Crowdstrike, Palo Alto Networks, and Fortinet.
Where do the largest data companies fit?
One of my goals of this article was to provide a clear picture of where popular data companies fit into the ecosystem. For the sake of brevity, I won’t describe each company’s offerings in depth, just simply show where they fit into the ecosystem. I’ll also note that this doesn’t discuss product quality, feature richness, or revenue by product; simply product availability.
Starting with the cloud companies, as they have the broadest data offerings:
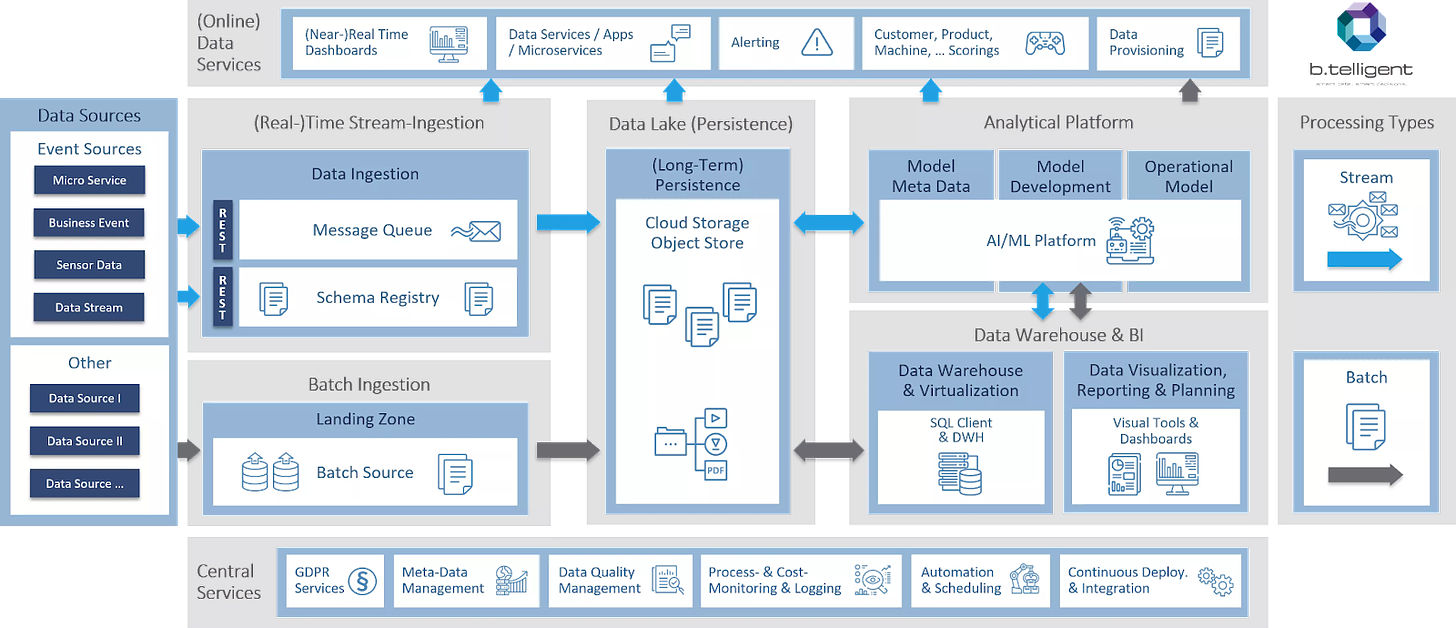
Amazon
Their services cover the entire span of the data value chain.
S3 is the leading object storage by market share, and they offer solutions across the storage space.
They’re behind the other cloud providers in AI/ML and it will be interesting to see how their offering develops.
Another weakness is the lack of a unified security solution and unified governance solution.
From my observations, they opt for a partner-first strategy where they support cloud partners like Crowdstrike and Datadog instead of prioritizing first-party products.
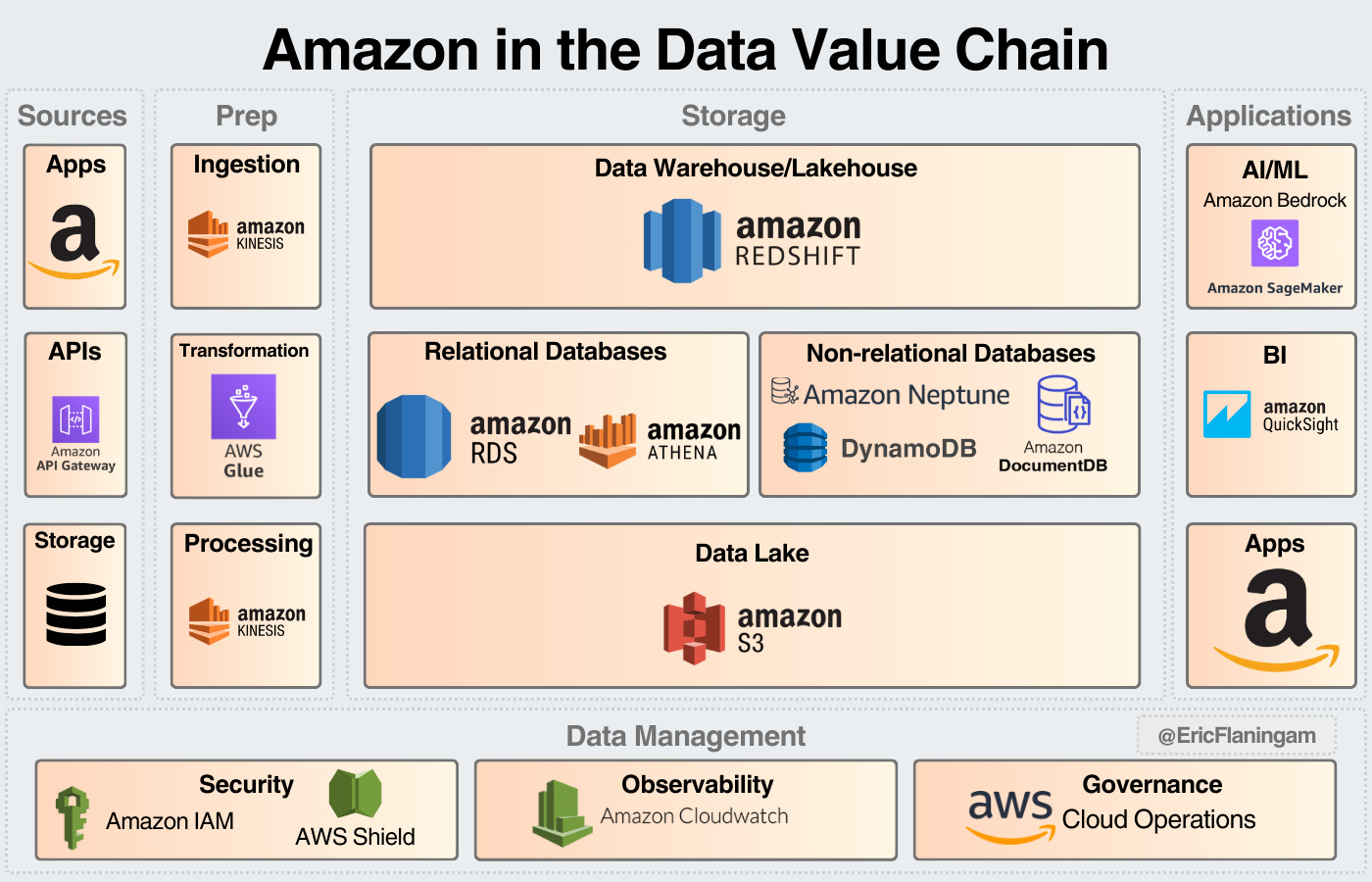
Microsoft
Microsoft also covers the entire span of the data value chain.
For storage: they have a top 5 data warehouse product, the second largest relational database system in the world, and a competitive NoSQL product.
They also have a product for security, observability, and governance.
On top of this, they have leading AI & analytics tools in Azure OpenAI, Power Bi, and Copilot (as has been well publicized).
They don’t have a clear weakness in their data ecosystem and the data business generates an estimated $20B annually.
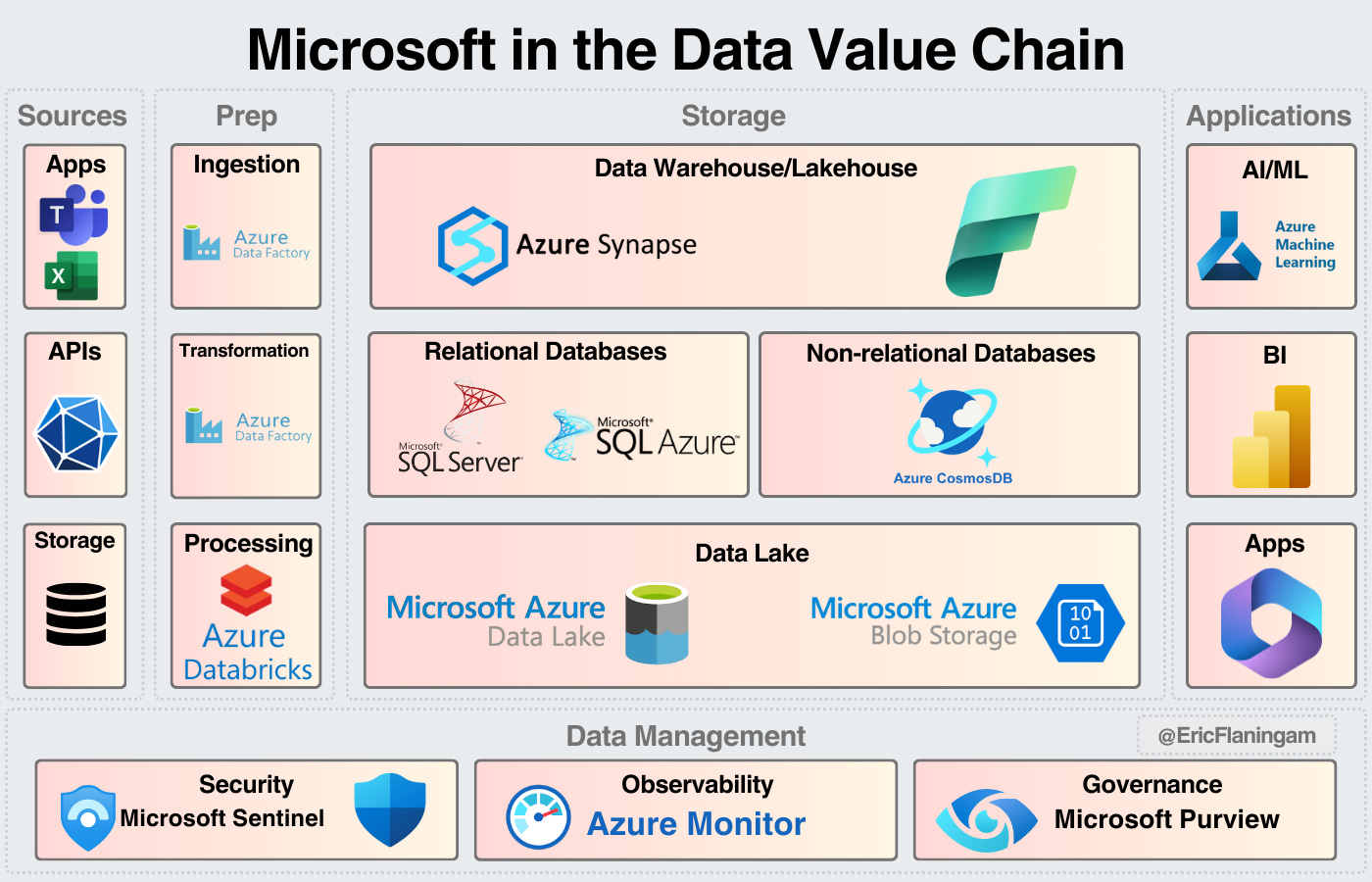
Google, for years, has been one of the most innovative data companies on the planet.
They offer services for each major step in the data process.
Their goal is to be the cloud for Data & AI; up until this year, they were executing excellently on that vision.
Despite slowing growth, GCP is still growing at 20+% annually.
Their inventions have been critical to AI innovation and they are primed to play an important role in the future of data.
They continue to expand their platform to be as expansive as any other data company, acquiring both Looker and Mandiant over the last 5 years.
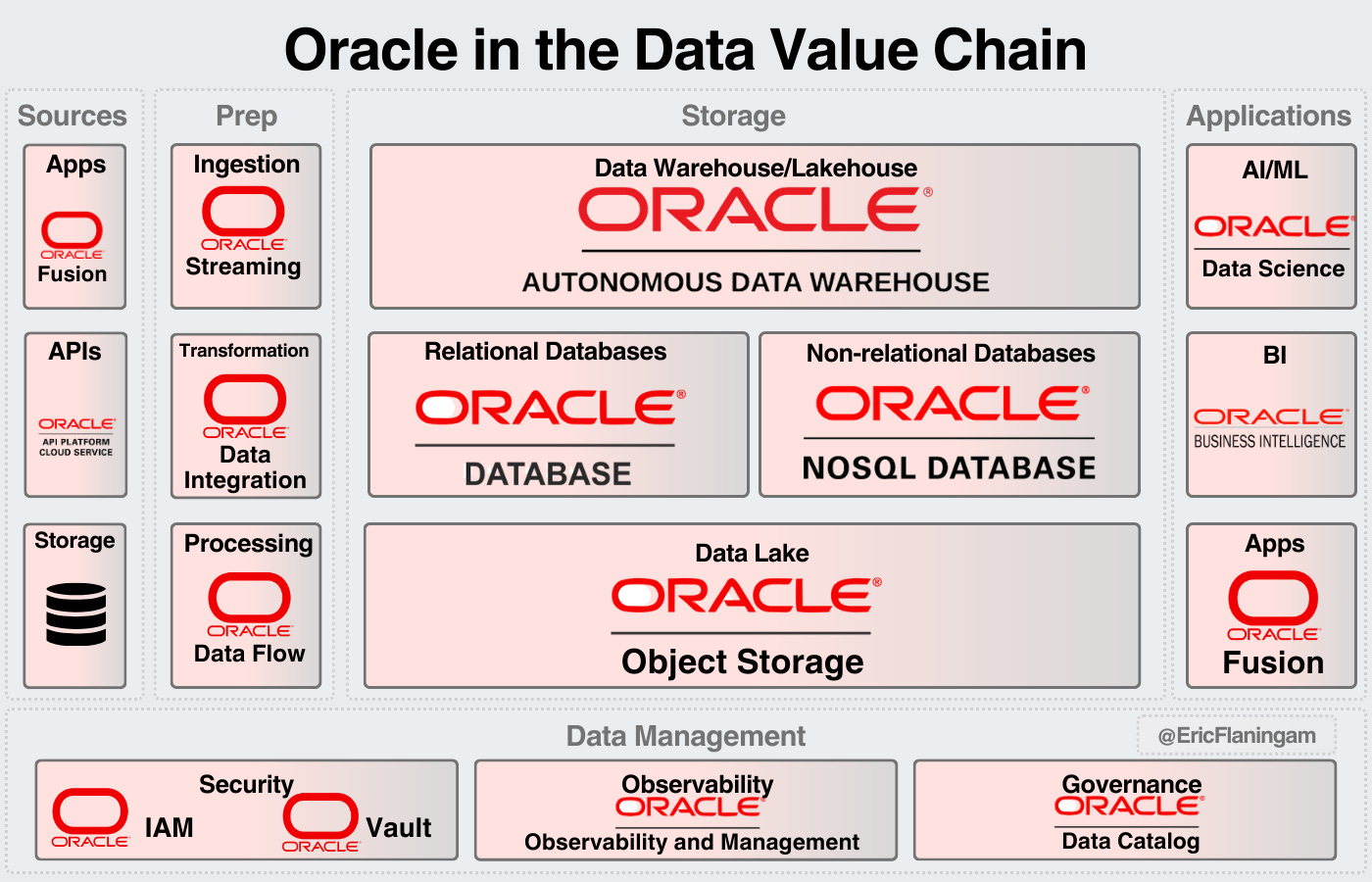
Oracle
Oracle has been a leading data company for 40 years now.
While Oracle is seen as a legacy data provider, they do have an impressive portfolio of products.
They offer products across the data value chain.
Much of their business is still on-prem, and they have a huge customer base to upsell to their cloud service.
Oracle has the highest market share of any relational database management system.
With how integrated data services are into company ecosystems, Oracle is likely to continue to be an important player in the data market for the foreseeable future.
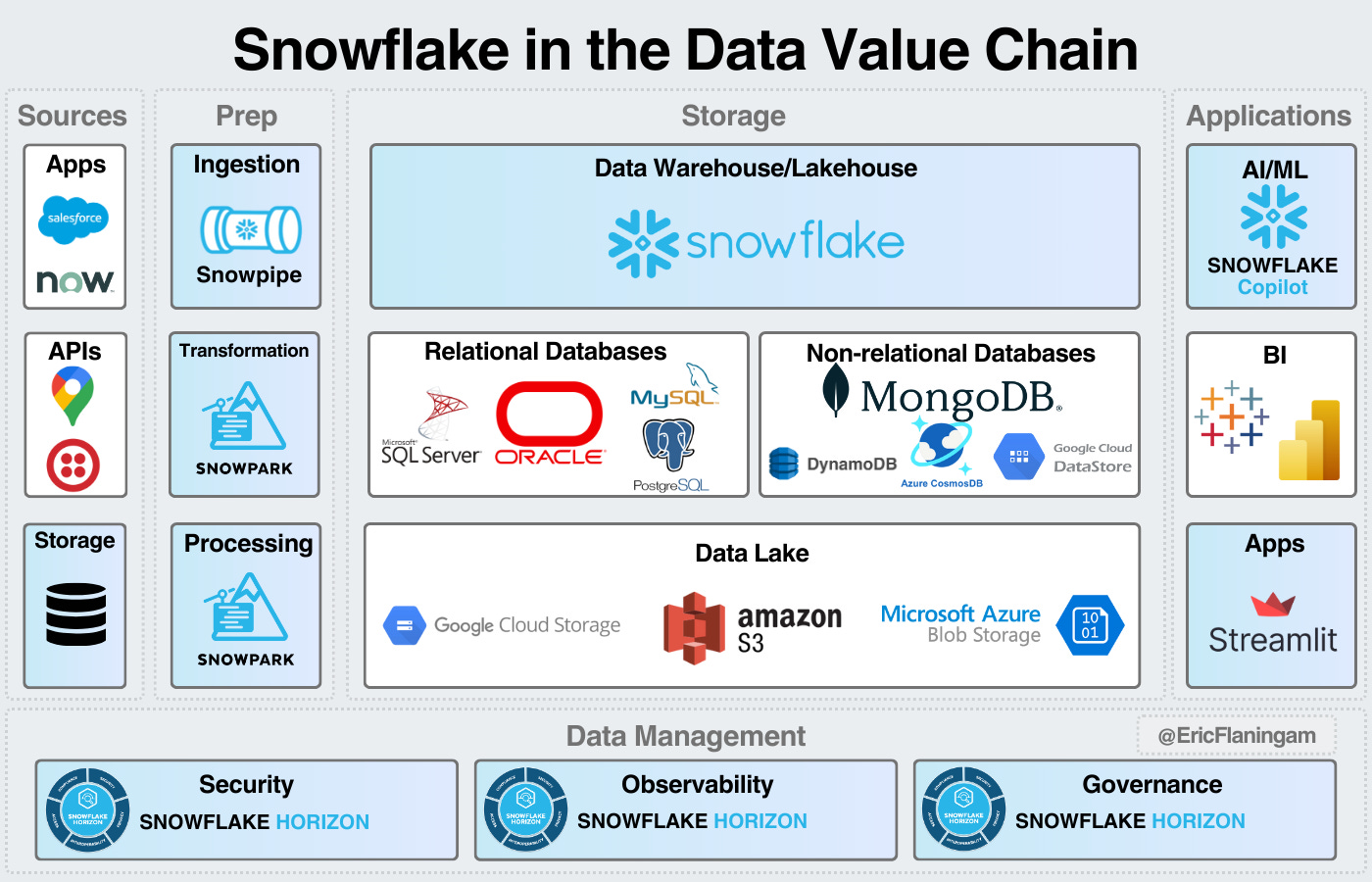
Snowflake
Snowflake’s core business is the data warehouse, but they’re aggressively expanding their offerings.
As Frank Slootman says:
We've been working very hard…in delivering just an absolute ton of capabilities to enable these platforms and all these different directions.
Security & governance provide an important market expansion with Snowflake Horizon.
As they continue to provide more support for unstructured data, they are enabling Snowflake to manage all the storage needs for an organization.
We’ll also continue to see more feature enhancement in security, governance, and AI/ML.
In a fragmented data industry, Snowflake is as well positioned as any pure-play data platform to succeed.
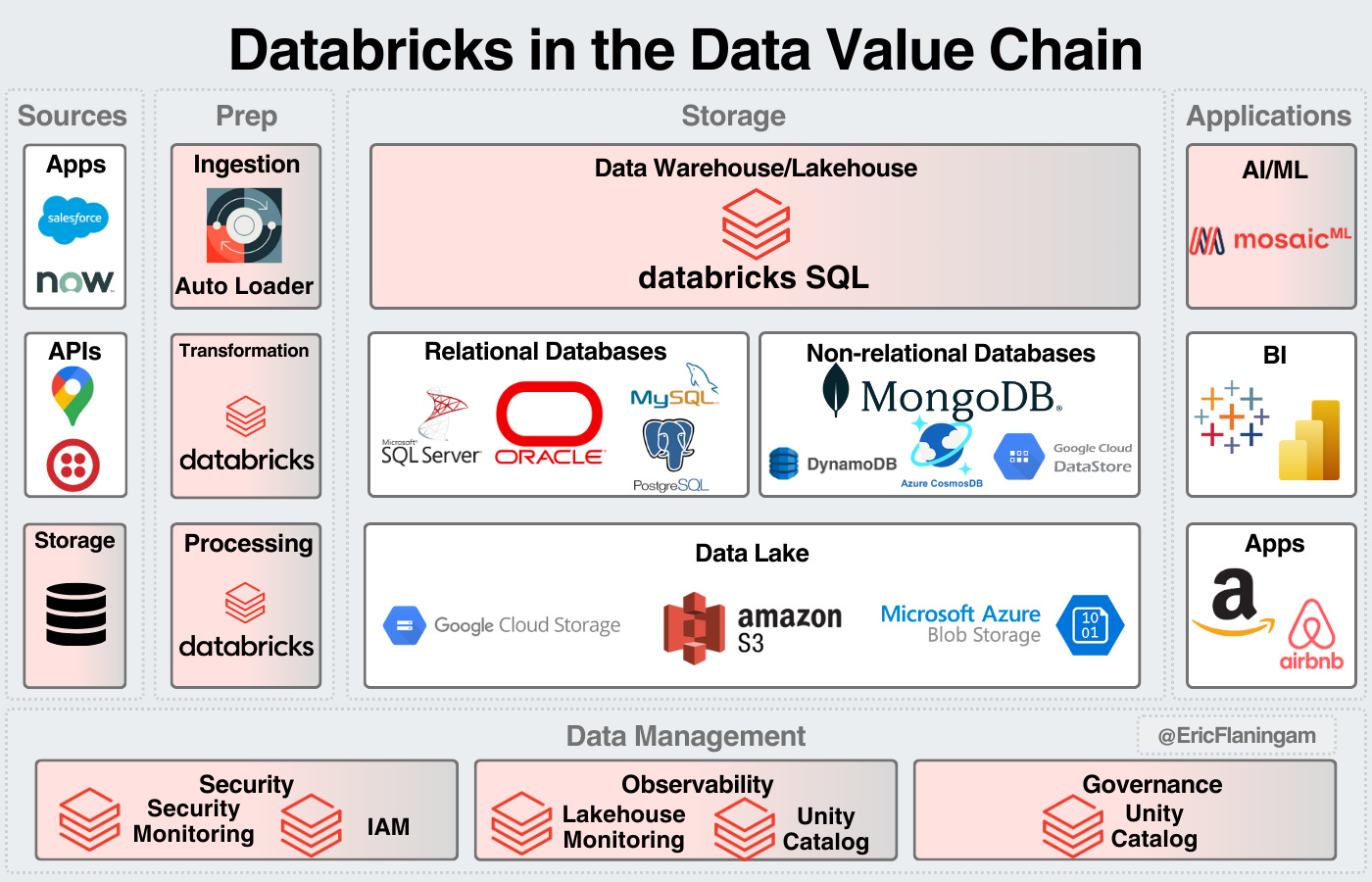
Databricks
Databricks was built around Apache Spark for big data processing and enabling the ingestion of real-time data into data platforms.
Databricks then built an ecosystem around enabling the end-end data flow of ML/AI.
Now, Databricks competes with Snowflake and the cloud providers to be the central data provider for an enterprise.
Much of their offering is providing managed services for open-source tools.
Databricks then becomes the central data platform to integrate all those tools into it.
It’ll be one of the biggest tech IPOs ever when they decide to IPO.
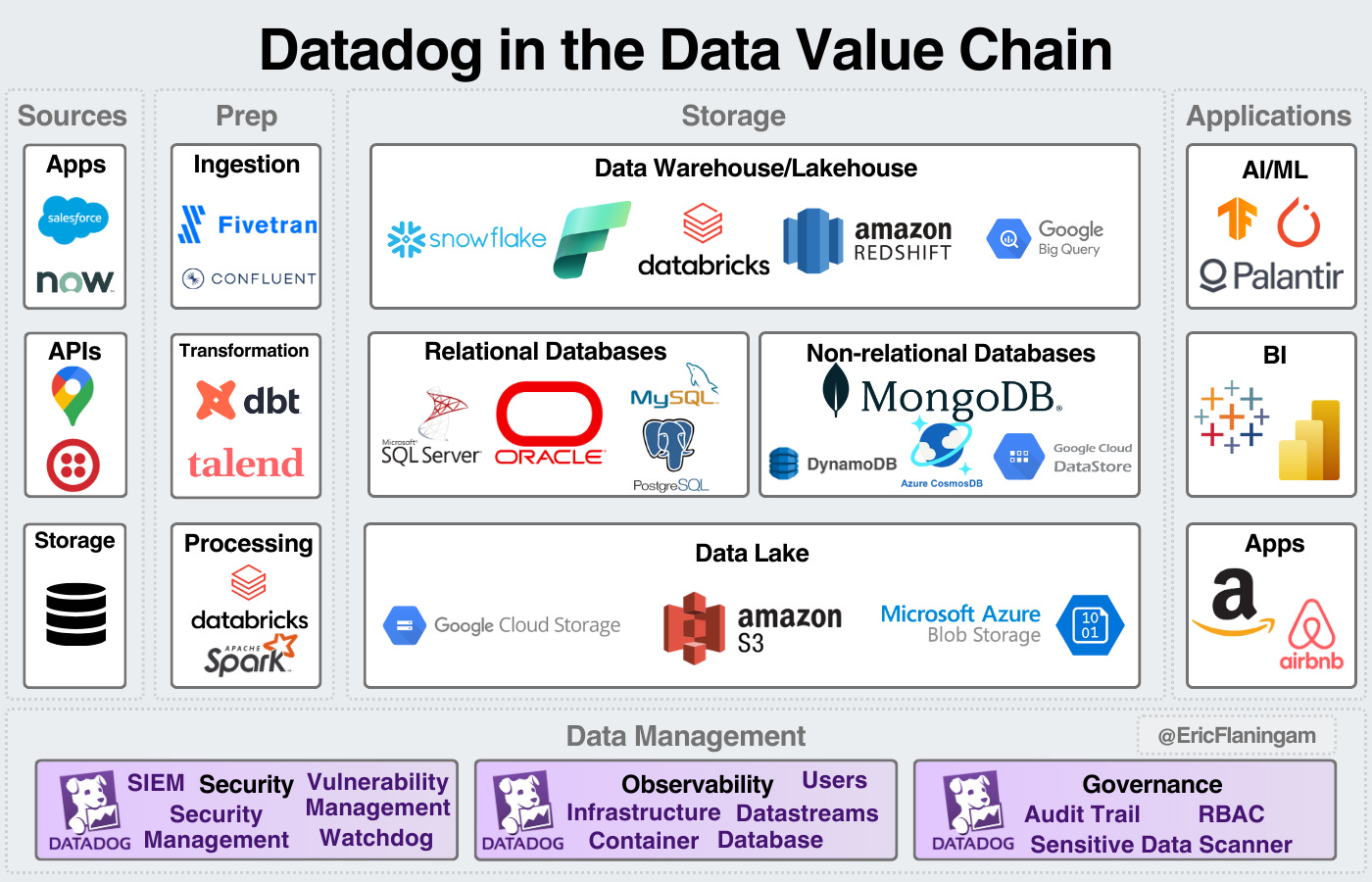
Datadog
Datadog’s original product was cloud infrastructure monitoring, designed to detect anomalies in cloud operations.
Since then, they’ve expanded to provide 30+ products across security, observability, and governance.
Their goal is to dominate the security and governance layer for the cloud.
The platform they’ve built out is expansive, and they’ve done an excellent job marketing as well.
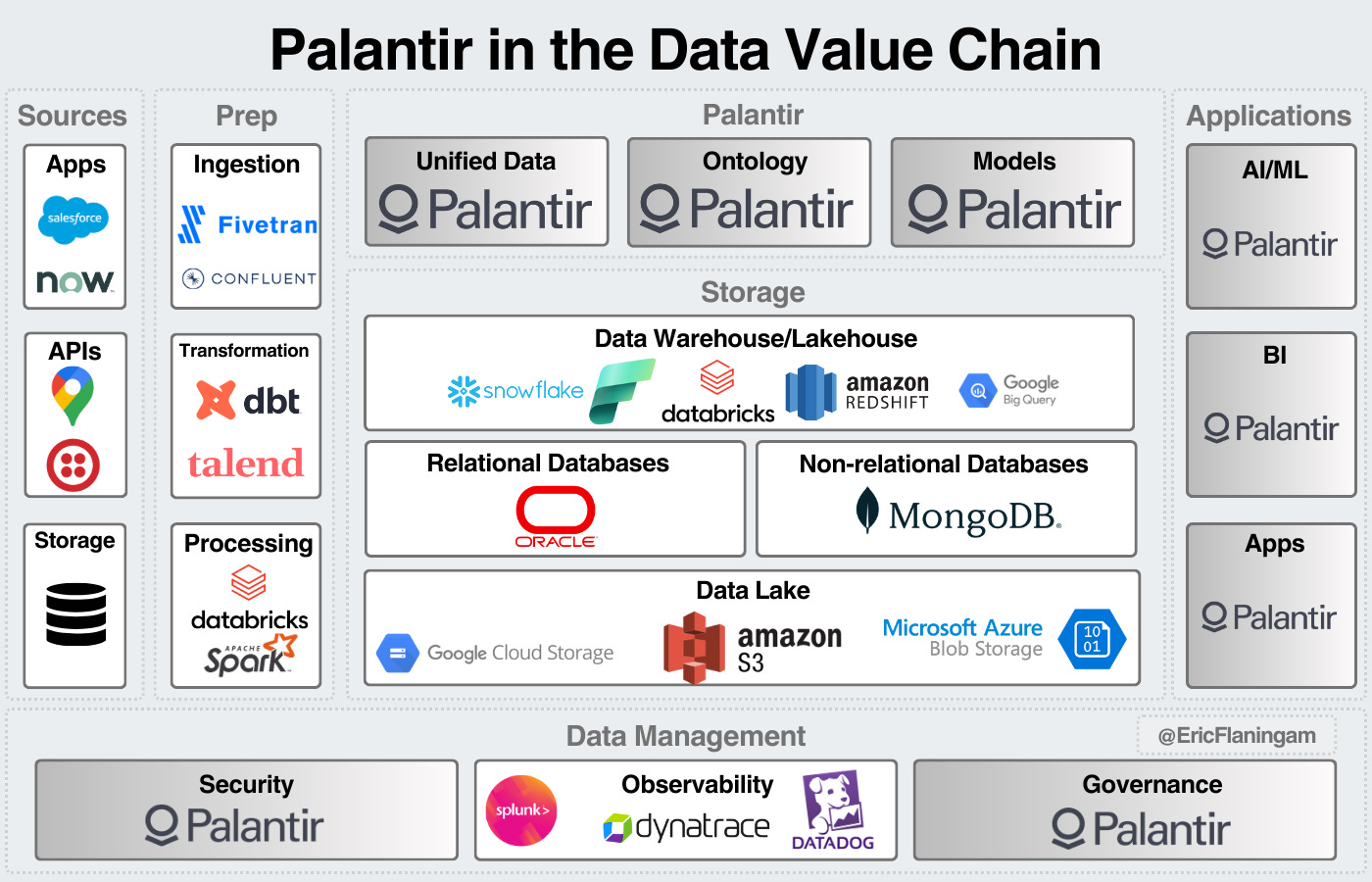
Palantir
Finally, I wanted to touch on Palantir, they’re an interesting company to fit into the data value chain.
For the most part, they compete in their own lane compared to other data vendors. They provide an end-end data solution from data to applications that sits on top of the storage layer.
They start by integrating their data into a unified layer. Model development sits on top of that. A data organization layer called ontology then mirrors the data estate of the company. From there, workflows, visualization, and applications are built to make business decisions.
Public Comps Datamaintaining
Lastly, I want to share Public Comps data on these companies. For the sake of brevity, I’ll share data on Snowflake and readers can explore other SaaS companies on the platform.
You can find dashboard comparisons here.
Snowflake is one of the most expensive stocks on the market:
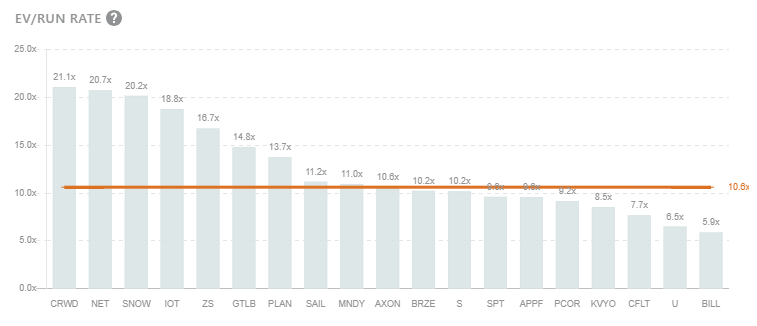
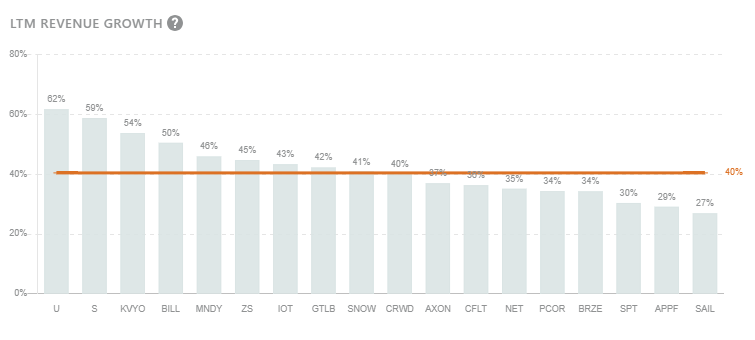
This is with good reason with Snowflake’s huge TAM, high NRR and strong growth:
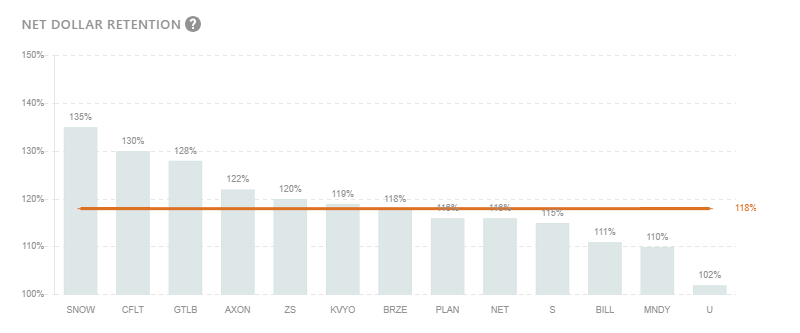
Finally, Snowflake is working its way to profitability with increasing gross margins and FCF, while maintaining best-in-class NRR.
A final note on how I currently view investments in the data landscape:
As a long-term public investor, my goal is to find opportunities with wide moats that are likely to perform well as a business for the next decade. This is a challenging proposition in the data industry.
VCs, on the other hand, have the opportunity to look for companies solving a specific problem. There are still lots of problems to be solved in the data space. With the SaaS model, it’s easier to relatively quickly scale up a business. These companies can then attempt to carve out a niche in the industry, IPO, or be acquired by one of the large data companies. This is an extremely attractive, fast-growing space, for private investors.
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. I’m a Microsoft employee, all information contained within is public information or my own opinion. I hold shares of Microsoft, Amazon, and Google.