A Primer on the Data Lakehouse


The data lakehouse emerged in the late 2010s as a cheaper, open-source, flexible alternative to the data warehouse. While the data warehouse consolidates compute/storage/services, the lakehouse architecture breaks up those offerings into individual components, typically based on open-source software.
My goal for this article is to give readers a ‘0 to 1’ understanding of the data lakehouse's history, technology, and market landscape. This is the third article in a series of data posts, you can find the other two here:
I’ll be structuring the article as follows:
- Intro to the Data Lakehouse & Why it Gained Momentum
- History of the Data Lakehouse
- Overview of Lakehouse Technology
- Overview of Lakehouse Market
- Public Comps Data
As always, I like to make the disclaimer that I’m an investor studying the space not an expert on any one industry. My goal is to understand industries and look for potential investments, and I hope to share some of those learnings along the way.
You can find my other articles on the Public Comps Blog or my Substack.
1. An Intro to the Data Lakehouse
At its core, the data lakehouse disaggregates the data warehouse into it’s fundamental components: storage, compute, and services. It allows companies to build their preferred data stack with the tooling they choose, typically open-source software.
The data lakehouse is an architecture, not a specific technology. It’s a way of structuring data management, not the data management itself.
We can visualize its role in the data value chain here:
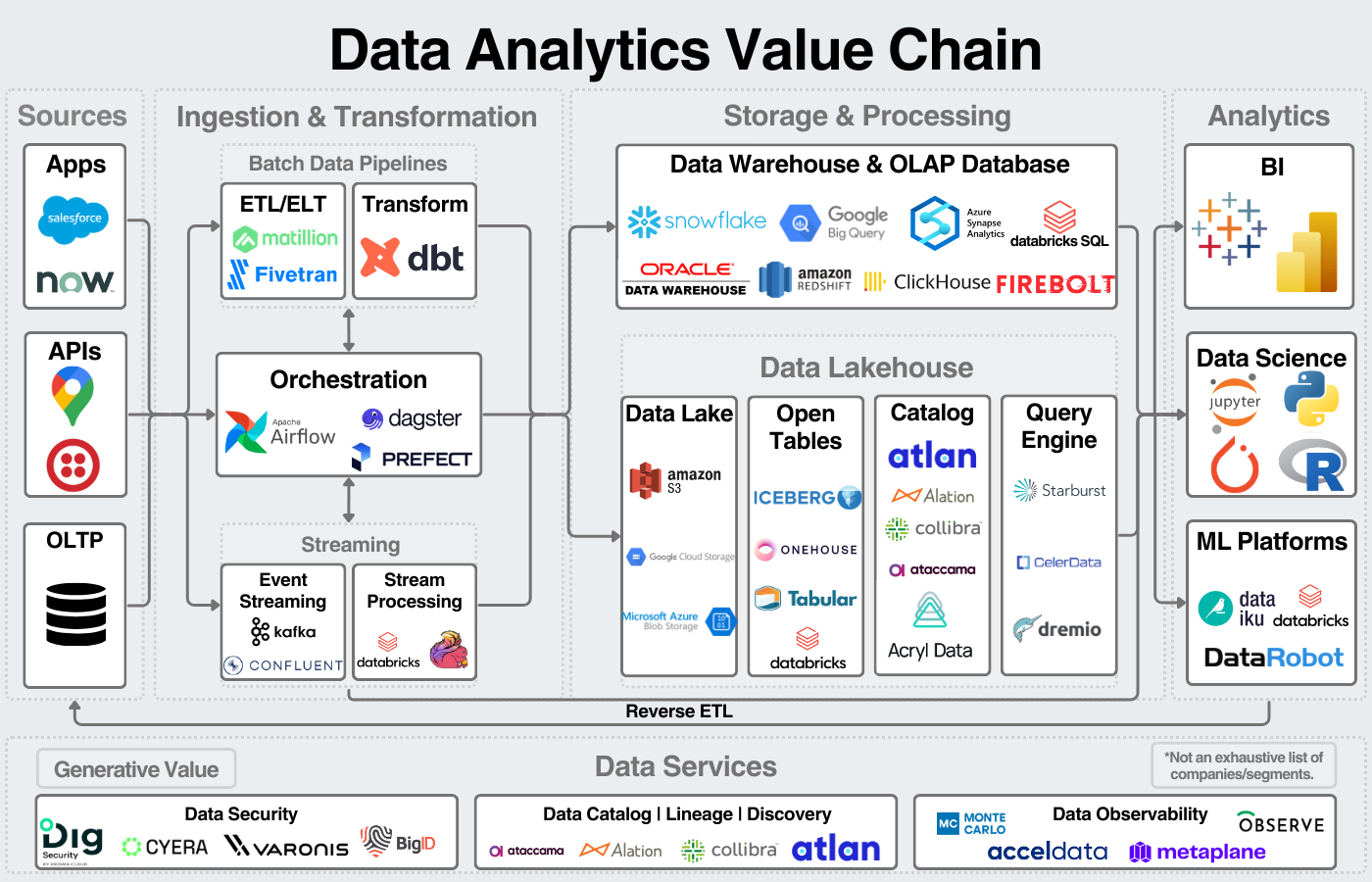
On the surface, the data lakehouse emerged for a few reasons:
- Data warehouses were expensive, closed-source, and didn’t handle unstructured data well.
- Data lakes were difficult to manage, leading to data disorganization.
The lakehouse merged the data lake and the data warehouse bringing three primary benefits: centralizing data management onto one platform, opening the data platforms to open-source tools, and doing so at a theoretical cheaper price.
If you’ll allow me a theoretical detour, I think the emergence of the lakehouse stems from a more fundamental theory on Clay Christensen’s evolution of industries.
When an industry is born, it’s typically brought to market by a single vertically integrated company that invented the original technology. This company must be vertically integrated because the market isn’t large enough to justify smaller companies taking segments of the market. Over time, as the market grows, it justifies competition entering into the market and attacking the least defensible parts of the vertically integrated company.
Typically, this happens over time. The vertically integrated company will continue to secede its least profitable and least defensible business segments until it retreats around its core IP and most valuable offering. This is what I consider the true value or “secret sauce” of a company. (When I study companies, this is the key question I’m trying to understand.)
The evolution of the lakehouse provides, in my opinion, a perfect example of the evolution of industries. Cloud-based data warehouses offered integrated data services; lakehouses broke up that paradigm allowing competition to enter each segment of the data warehousing market at once.
2. History of the Data Lakehouse
For a deeper history into the early years of the data analytics industry, you can read my article on data warehouses. I’ll start here with the emergence of the cloud and the data lake.
Hadoop, the Cloud, and the rise of Big Data
Three variables led to the rise of big data platforms: the internet, the cloud, and data processing frameworks.
The rise of the internet led to more amounts and complexity of data than ever before. Companies were attempting to manage this data with different on-prem databases and data warehouses; however, these tools were not built for this scale of unstructured data. With this rise of “big data”, companies found they needed analytics on increasingly large amounts of data.
In 2006, Hadoop was released as an open-source distributed data processing technology (meaning it could process large amounts of data across multiple machines and was free for everyone). Hadoop is a collection of software for big data processing which includes MapReduce (algorithm for processing), Hadoop Distributed File System (big data storage system), and YARN (job scheduling).
Around the same time, AWS released its first product: simple storage service or Amazon S3. S3 provided cheap object storage for unstructured data that could be accessed over the internet. It provided essentially “unlimited” data storage.
With these three things, companies had large amounts of data to store, a way to store it, and a way to process it. This led to the advent of the data lake - a central repository for a company’s data.
Apache Spark & the Cloud Data Warehouse
In the late 2000s, Spark was created by a team out of UC Berkeley (who would go on to found Databricks). Spark provided an alternative data processing framework to Hadoop and quickly gained traction in the data science community for training machine learning models, querying big data, and processing real-time data with Spark Streaming. Databricks was founded in 2013 by the original creators of Spark (who would also invent Delta Lake and MLflow).
In 2012, Amazon released Redshift, an early cloud data warehouse. It provided an alternative to on-prem data warehouses and became the early market leader. Two years later, Snowflake was released. Snowflake de-coupled compute and storage meaning that compute (running queries/processing date) and storage of data could scale independently. This allowed companies to optimize Snowflake for their specific use cases - either storing large amounts of data or running many analyses. Snowflake combined this with elite user experience to become a leading cloud data warehouse.
Snowflake and Databricks initally offered different value propositions. Snowflake offered an “iPhone-like” experience for data analytics workloads while Databricks enabled machine learning and focused on the developer. Despite their different value propositions, their paths inevitably converged. Their rivalry would go on to help define the modern data era.
As Ben Rogojan points out, this narrative is exactly how they like it:
The Rise of the Data Lakehouse
In 2020, Databricks announced their vision for the data lakehouse.
The goal of the lakehouse was to solve two problems:
- The cost and inflexibility of the data warehouse.
- The management difficulties of data lakes.
The lakehouse paradigm offered the ability to merge data lakes and warehouses and run analytics directly on the data lake.
Prior to the lakehouse, a typical architecture would ingest data into a data lake, transform it, load it in to a data warehouse, and run analytics from there.
The core idea of the lakehouse was to keep all of a company’s data in the data lake and bring the analytical capabilities of the data warehouse to the data lake. This centralizes the storage/management of data, removes the complexity of managing both storage units, and reduces the cost of data duplication.
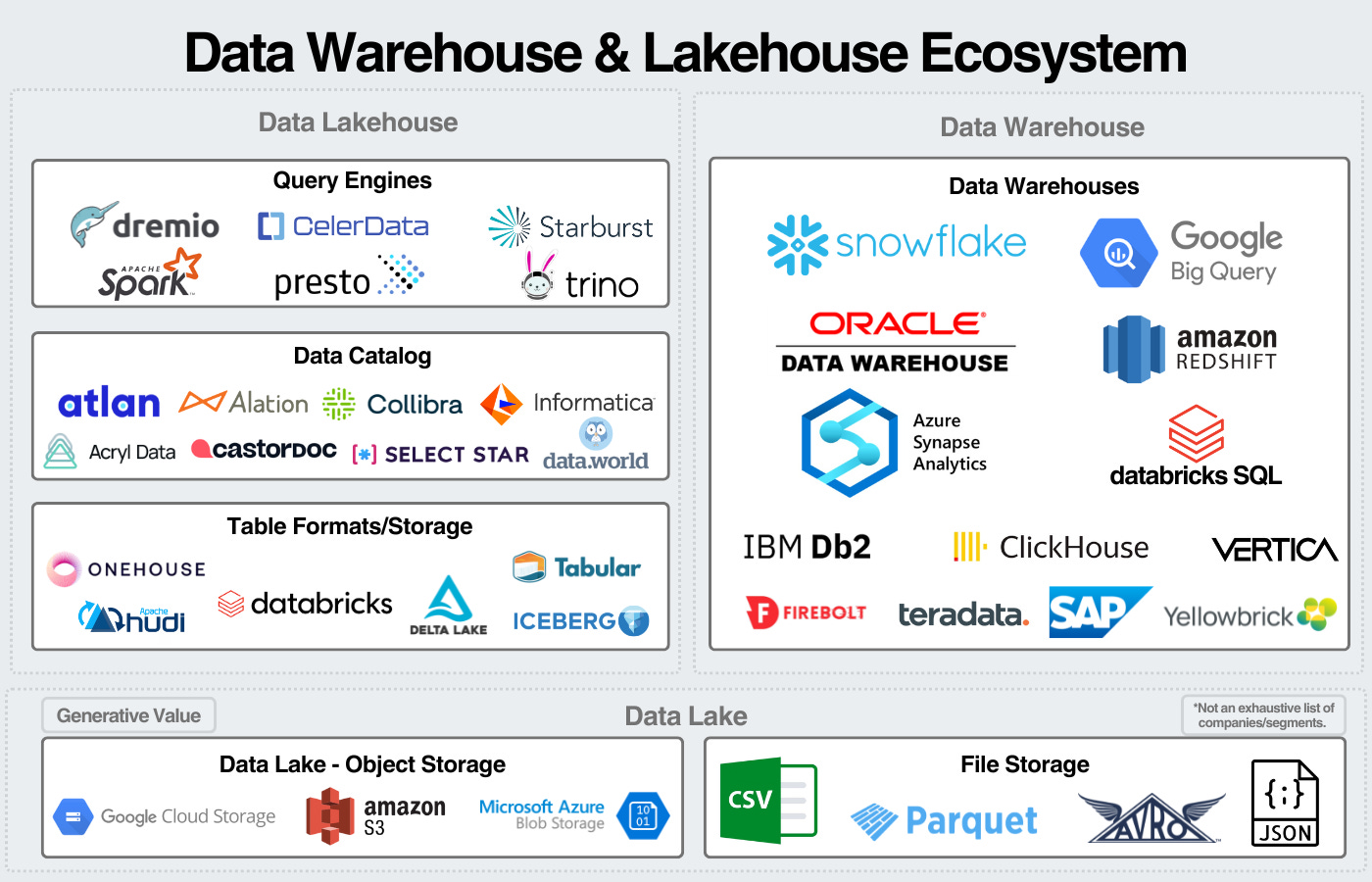
This results in a deconstructed data warehouse, ran on the data lake, with open-source technologies. In large part, this has been enabled by the development of technologies that are able to complete individual tasks of the data warehouse. Query engines like Dremio and Starburst providing a compute engine to analyze data. Open table formats like Delta Lake, Iceberg, and Hudi provide structure and a way to transact with the data lake. Metadata management platforms like DataHub and Atlan provide a way to simplify data management (governance, lineage, observability, discovery, etc.). Combining all these tools together bring us to the modern version of the lakehouse.
3. Overview of the Data Lakehouse
I think about the lakehouse in four segments:
- Storage - Storing and organizing data in formats that can be analyzed.
- Data Catalog - Organizing metadata to effectively manage the underying data.
- Compute & Querying - Executing queries against the data.
- Data Services - Managing data for security, governance, and other services to maximize the value of data.
Disclaimers:
- Since the lakehouse is a paradigm and not one technology, the technologies “included in the lakehouse” differ based on who you ask.
- The image does not encompass all companies/segments. Additionally, companies may compete in multiple segments but only be included in one.
- I view this as a mental model, not an encompassing market map; I encourage readers to do the same.
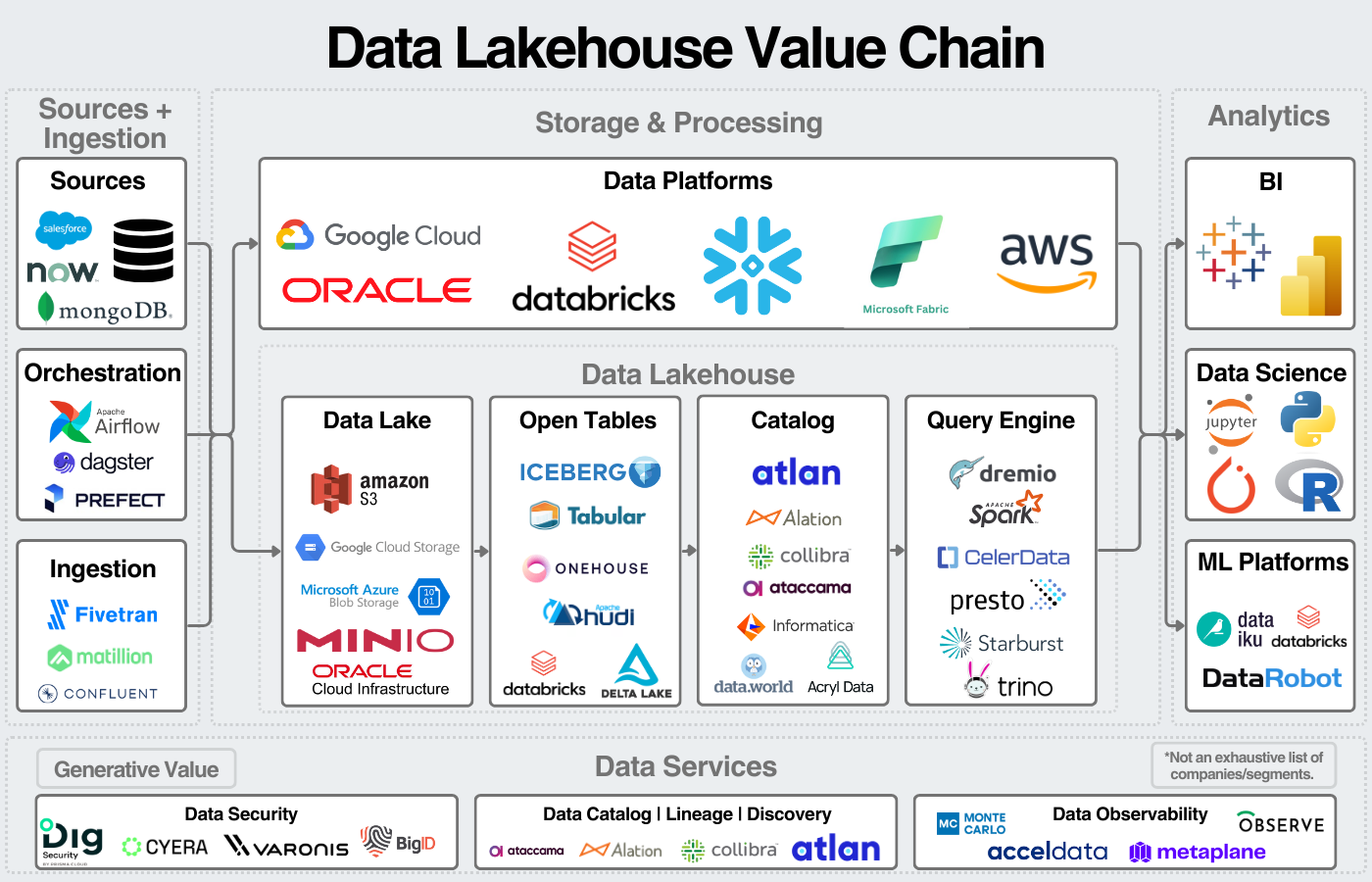
Storage
Storage refers to the location, file type, and structure of the data. At the base layer of data storage, we have the data lake. The data lake contains data stored in files like CSVs, Parquet, Avro, JSON, or ORC. Those files are then stored in cloud object storage like Amazon S3, Microsoft Blob, or Google Cloud Storage. Analyzing data in this form is challenging, enter open table formats.
More on cloud technology here.
Open table formats like Iceberg, Delta Lake, and Hudi provide a metadata “wrapper” around the underlying object storage. This enables the ability to interact with this data similarly to if it was in a tabular format. Open tables have been a relatively recent phenomenon that have gained a lot of momentum. Iceberg was released in 2018, Delta Lake in 2019, and Hudi in 2019. These are the three primary open table formats on the market. Xtable is an incubating project released by Microsoft, Google, and OneHouse to enable interoperability between the three table formats.
Databricks, with their acquisition of Tabular, unified the founding teams of Iceberg and Delta Lake. At the same time, they effectively eliminated an upcoming competitor and prevented a path for Snowflake and Confluent to expand in the data lakehouse. Excellent strategic move (although at a hefty price).
Data Catalogs & Data Management
On top of the storage layer, we have the data management layer. Some people call this the semantic layer or the metadata management layer; the key point is that this layer provides the products to organize and track the data in the data lake. If open table formats create metadata wrappers around data, then the data management layer centralizes that metadata and makes meaning of it.
On top of the data catalog, companies can then run a variety of data services on that centralized metadata. I’m particularly impressed by Atlan’s vision for the “active metadata layer” with the goal of using data catalogs as an active tool to manage company’s data instead of an after-thought governance tool.
The data catalog or semantic layer continues to grow in importance. If the data catalog is implemented well, organizing data becomes much easier. Without it, lakehouse architectures can become just as challenging to manage as data lakes.
This is why we’re seeing the chess moves by Snowflake and Databricks in the space.
- Snowflake and Databricks both pursue Tabular acqusition.
- Presumably, Databricks wins Tabular deal and Snowflake knows some amount of time before announcement.
- Snowflake announces “Polaris” open-source data catalog.
- Databricks announces Tabular acquisition.
- Databricks open-sources Unity Catalog.
What a time to be studying the data space.
Compute & Query Processing
Compute refers to the tools that process queries (requests for data). These are typically called compute engines, analytics engines, or query engines. These engines take a request from the user (or application), plan how to execute that request for optimal performance, and then execute that request.
For example, Presto, a SQL query engine, works by having one “coordinator” and as many “workers” as necessary to process the query. The “coordinator” takes the request and plans how to execute it optimally. Then, the “workers” process that request. Serverless (or managed) presto engines will do this scaling automatically, meaning users submit the query, and the tool processes it.
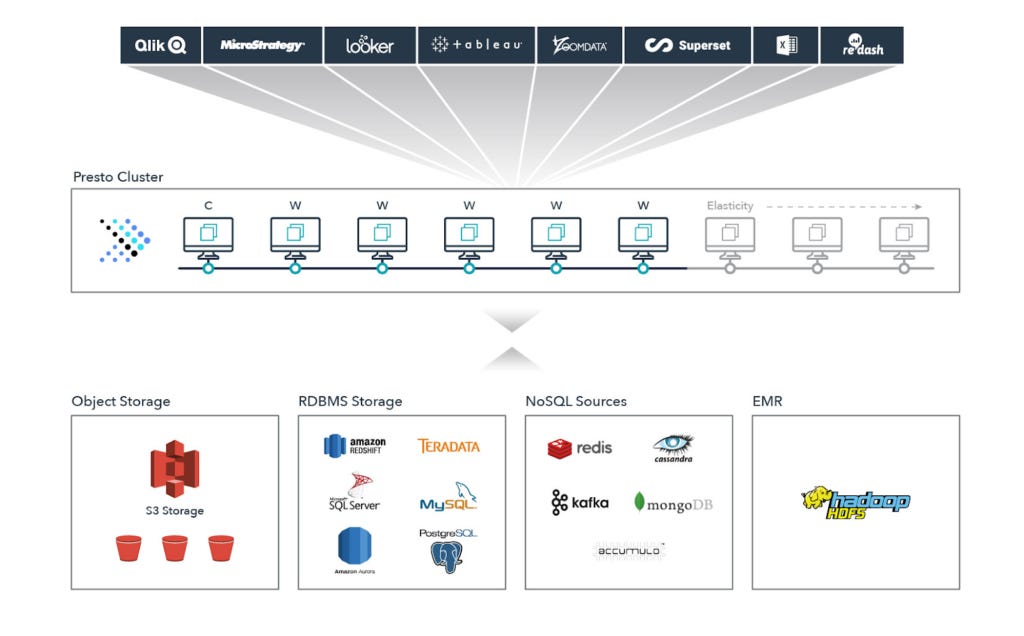
Open-source SQL query engines include Presto, Trino, Dremio, SparkSQL and StarRocks; managed offerings include Dremio, Starburst, and CelerData.
Other data processing engines also exist that aren’t specifically for analytics. Spark is the most well-known processing framework for processing data engineering, data science, and machine learning.
Services
Finally, a number of services are necessary to complete a full data platform. These services (outside of data services) include security, access management, and compliance tools.
For brevity’s sake, I won’t dive into each of these.
4. Overview of Lakehouse Market
I generally view the lakehouse market in four segments:
- Databricks & Snowflake
- The Hyperscalers
- Startups with a Wedge
- Warehouses Supporting Data Lake Queries
Databricks and Snowflake
When investors think of data companies, the two companies that come to mind are Databricks and Snowflake.
Although starting with different wedges, their competitive paths have converged. Databricks has expanded to data warehousing, Databricks SQL makes up an estimated 17% of Databricks’ revenue, growing 100% YoY. Since 2020, Snowflake has expanded their platform to encompass unstructured data workloads, data engineering, and MLOps; historically areas that Databricks has excelled in.
Snowflake has made it clear their intention to pursue more data in the data lake, saying in last quarter’s earnings:
“Data lakes or cloud storage in general for most customers has data that is often 100 or 200x the sum of data that is sitting inside Snowflake. Now with Iceberg as a format under our support for it, all of a sudden, you can run workloads with Snowflake directly on top of this data.” -
With that being said, Databricks is the 800 pound gorilla in the lakehouse. They invented important pieces of lakehouse tech, led the marketing of the lakehouse paradigm, and have been open-source forward since the beginning. When companies think of the lakehouse, they think of Databricks. Their vision is to bring “custom AI” to all of a company’s data, and the lakehouse is a key enabler of this strategy:
“What we want to do is create custom AI on all of your data. That’s what we call data intelligence…For that, we need all the data. The more data, the better.” - Ali Ghodsi
When they eventually IPO, it will be one of the largest IPOs ever.
Hyperscalers
Of the hyperscalers, Microsoft has the most direct strategy targeting the lakehouse. Microsoft Fabric is Microsoft’s flagship data platform and its a unified platform for the lakehouse. I’ll reiterate the goal of data platforms: one central location for the management of a company’s data. Fabric’s vision delivers this, but the question remains on execution.
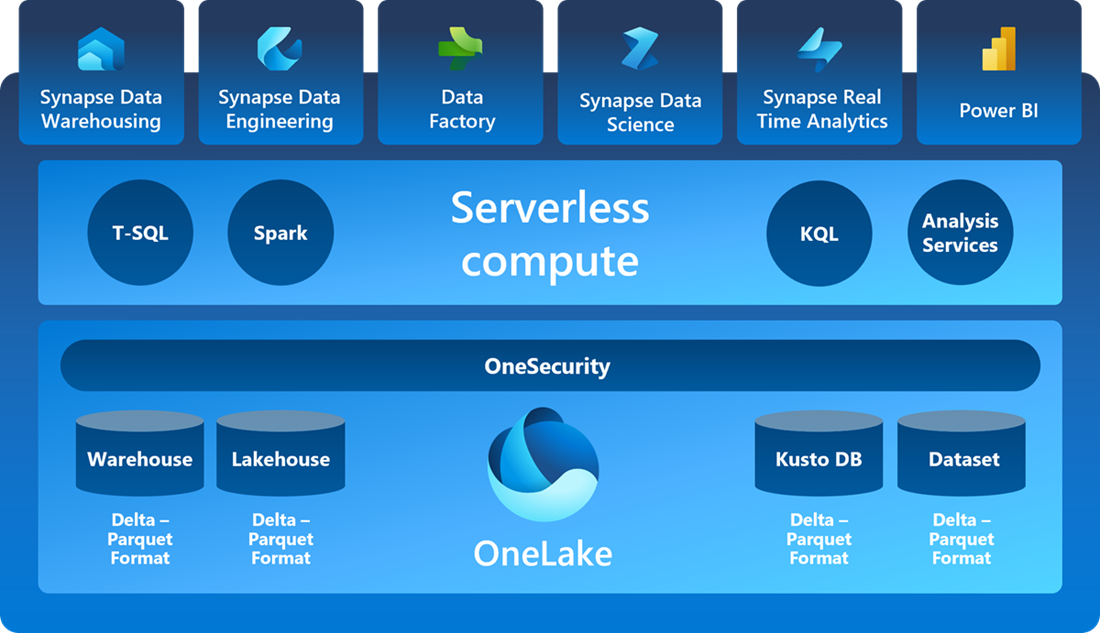
The other hyperscalers offer data lakehouse functionality allowing companies to build out their own lakehouses using the hyperscalers’ various services.
The more important note for the hyperscalers is that data is a multi-billion dollar product line for all of them. They have advantages from vertical integration and distribution networks that put them in a comfortable position to lead the data industry. The other *very* important note is that their role as cloud providers allows them to host open source software with better unit economics than their non-CSP competitors. IF software continues to trend towards open-source, the hyperscalers are in prime position to benefit.
Startups taking on the Lakehouse
Finally, a number of startups are pursuing wedges in the lakehouse. Most are offering managed open-source offerings taking on a specific layer of the lakehouse:
- Query Engines: Dremio and Starburst are two of the leading startups, both over a $1B valuation.
- Data Catalog & Services: Atlan recently raised at a $750M valuation, other startups include Acryl data, Select Star, Collate Data, and CastorDoc.
- Storage: Tabular and OneHouse were the two primary startups in this layer; Tabular got acquired recently and we’ll see if OneHouse follows suit.
I like to end these articles with some musings on the investment landscape.
5. Public Comps Data
Since we provide Public Comps, and the majority of lakehouse startups are private; we'll highlight Snowflake's data and patiently await a Databricks IPO!
Across public data companies we track, we can see LTM Revenue Growth, NRR, EV/Gross Profit, and EV/ARR among other metrics:
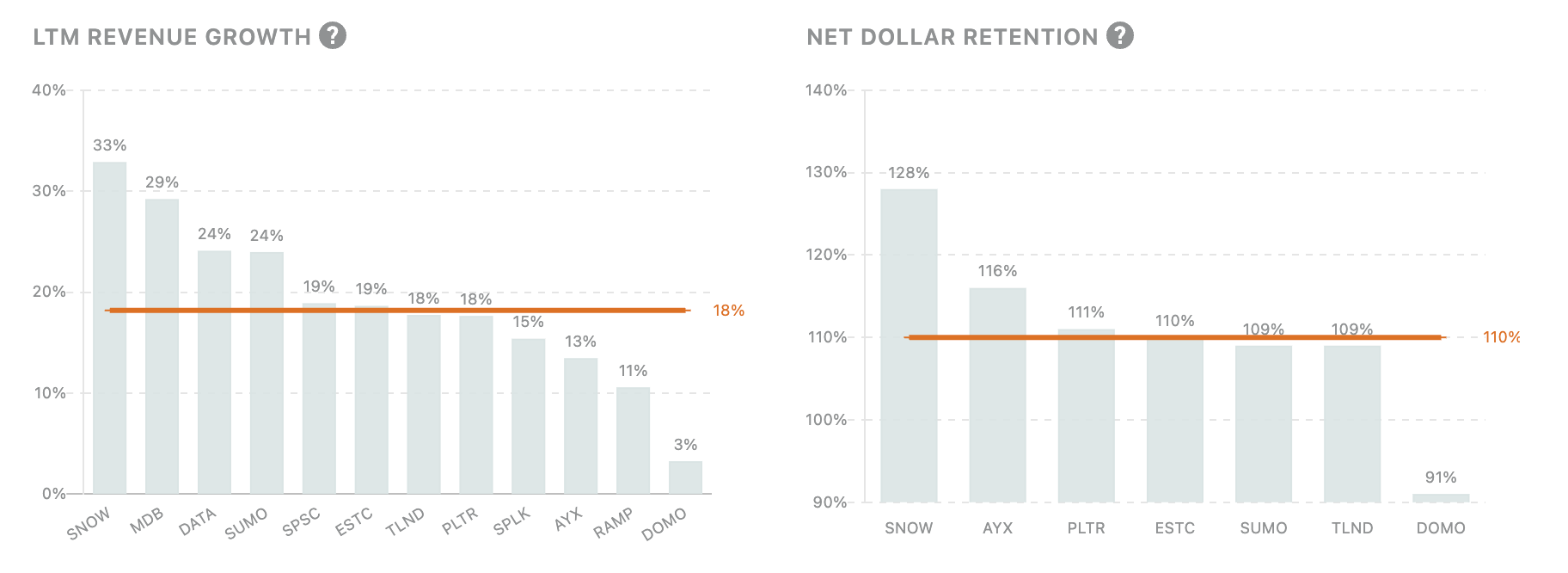
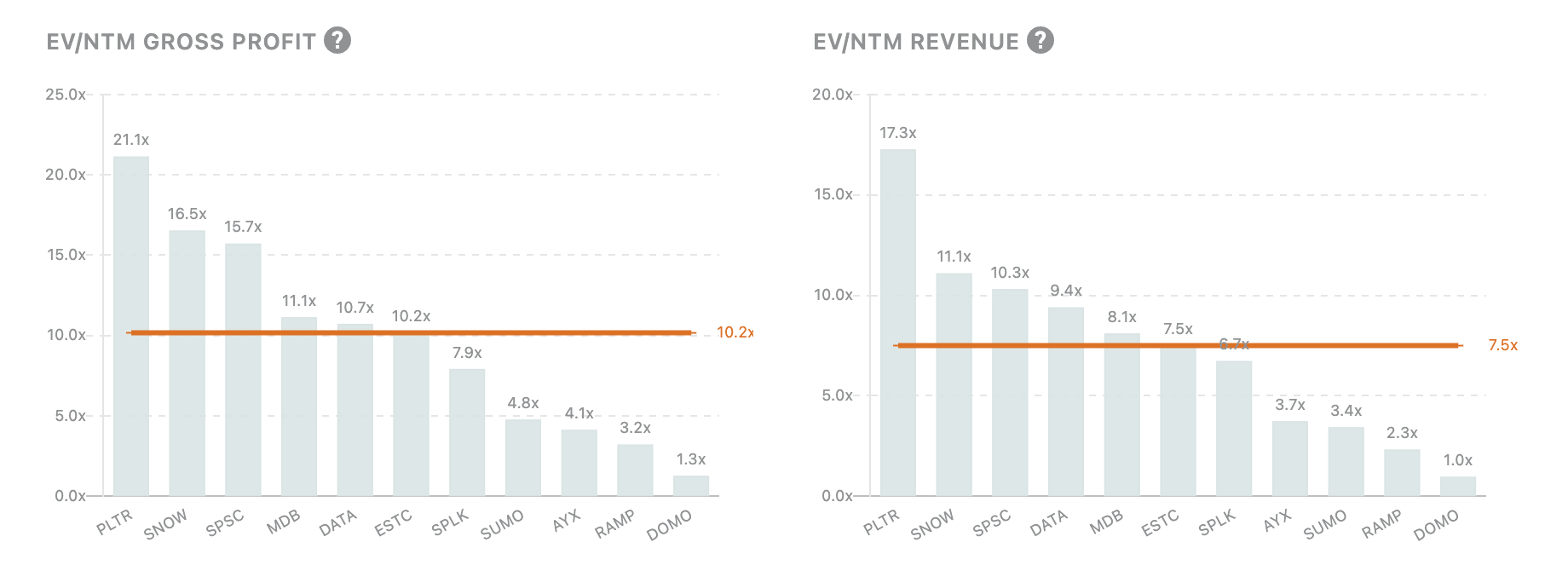
For individual companies, we can see public data filings and compare them to other comparable companies:
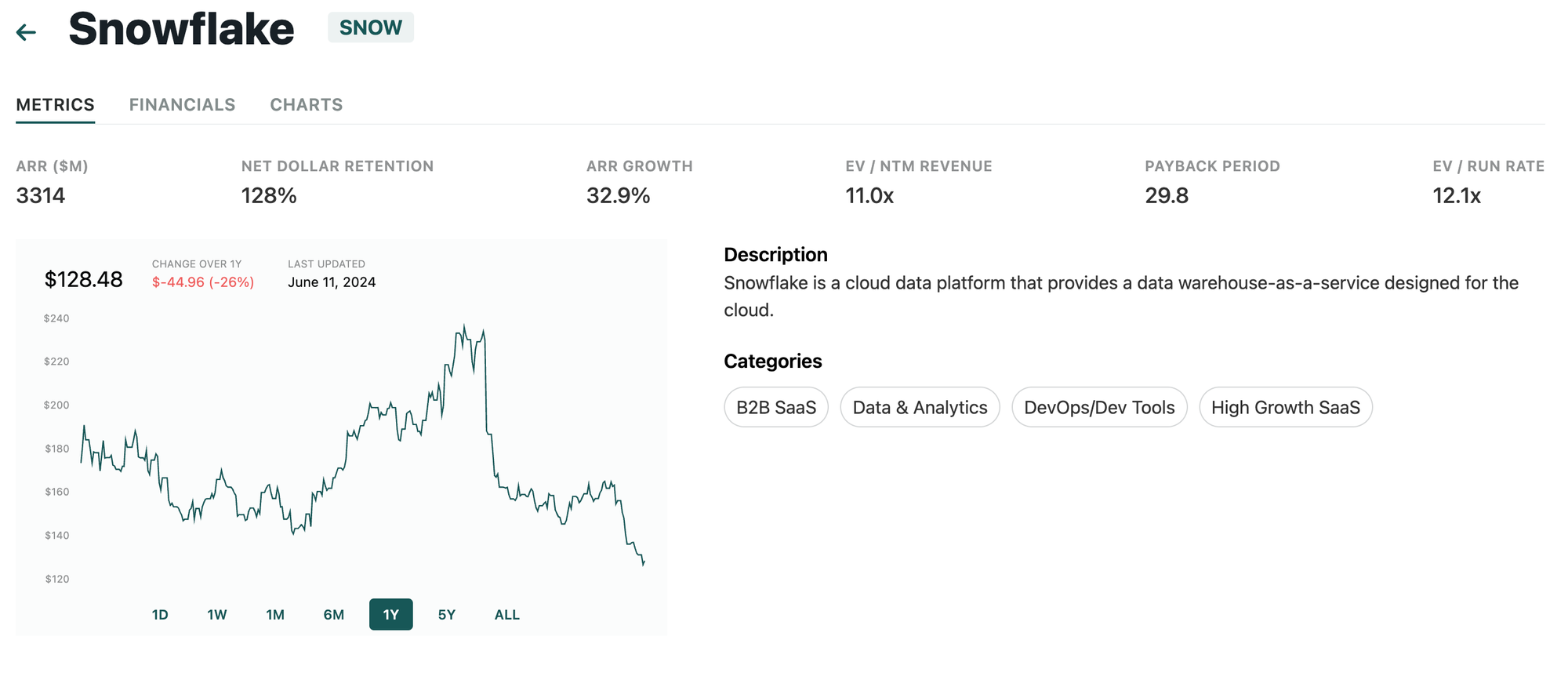
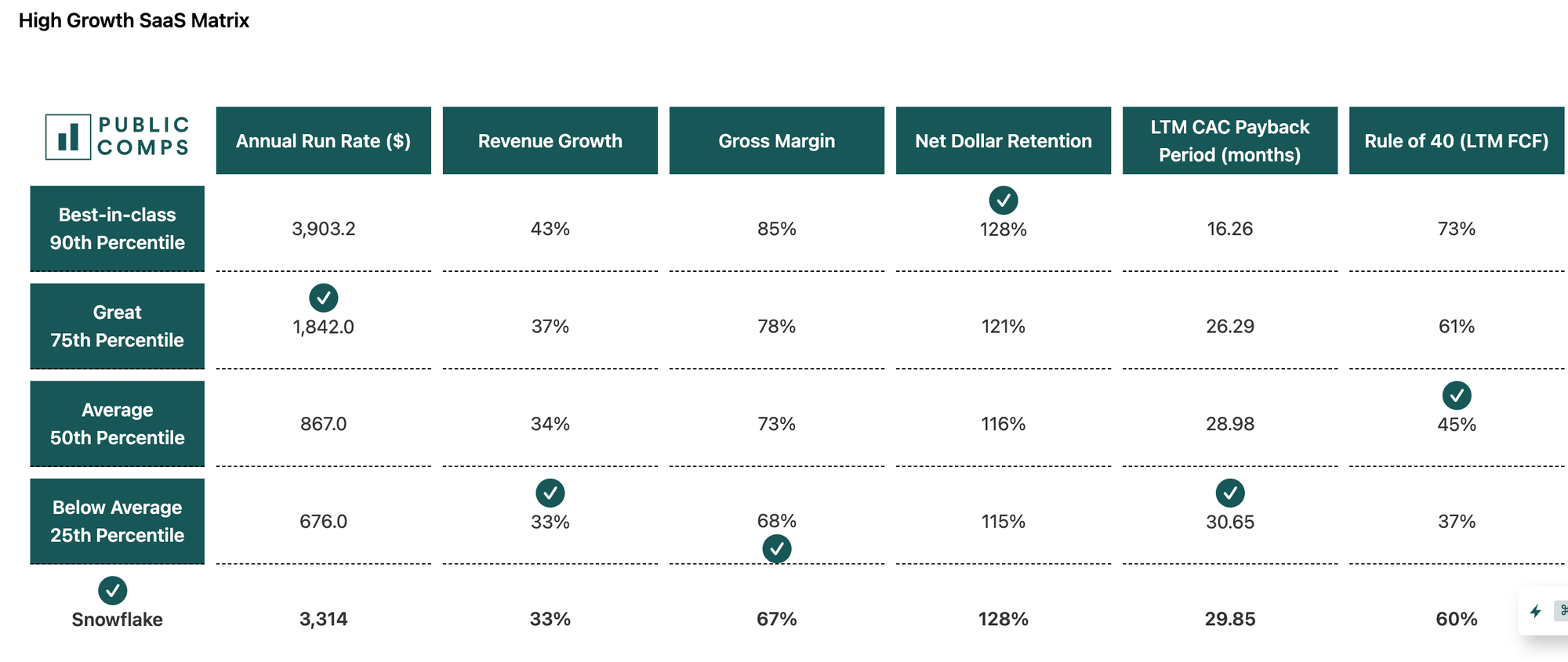
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed are solely my own, not those of Public Comps or other employers.