A Primer on Databases

Databases have underpinned much of the software movement we’ve seen over the last couple decades. They also happen to be one of the longest-running pieces of technology that still resemble their original form (at least for SQL databases). The data space caught my attention due to the inherent stickiness of data platforms and their potential to support the future of applications and AI.
This will be my last article (for the time being) on the data space. Combined, I think these four posts provide a strong basis for the industry:
- Data Industry Primer
- Primer on Data Warehouses
- Primer on Data Lakehouses
- Primer on Databases
I have drafts about data catalogs and data ingestion/transformation, and I may come back to those eventually. However, I believe the data industry as a whole is moving towards platforms, so the above articles cover the majority (not all) of the data platforms in the space.
My current areas of study are semicap, energy, and data centers (again). I expect my next article to be on the semicap industry, followed (I believe) by individual company analyses of the large semicap companies. But I digress, back to databases.
I’m breaking down this article as follows:
- An Intro to Databases & Their Relevance
- A History of Databases
- An Overview of Database Technology
- An Overview of Database Markets
- Public Comps Data
Disclaimer: As always, I like to make it clear I’m an investor studying the space and not a technologist. My goal is to analyze and simplify the space in a digestible manner as I “flip over rocks” for investment opportunities; I encourage readers to do the same.
You can find my other articles on the Public Comps Blog or my Substack.
1. An Intro to Databases & Their Relevance to Investors
Since the relational database was invented, software has been built on databases. Most software today has a database, a front-end, and a unique means of transforming/organizing data. Potentially, we’re moving to a world where not all software will be accessed via front-end web interfaces. Some software will be accessed via commands to agents who will execute tasks on your behalf.
In this world, the database still maintains its relevance.
From an investor’s perspective, we have companies like Oracle, IBM, and Microsoft who have 30-40 years of leadership in databases who generate billions of dollars from databases. Combined, we have a technology that will remain relevant for the foreseeable future and a history of companies showing sustained leadership in the field. Plus these products have strong margins, recurring revenue + service, and significant switching costs for customers. A recipe for intriguing businesses.
The technology of databases is relatively simple (at a high-level). Databases store information in a format that can quickly be utilized. Two primary use cases:
- Transaction Processing (OLTP): Store real-time information as a back-end for applications.
- Analytics (OLAP): Store large amounts of data to be queried for finding insights across that data.
Broadly, the database market is broken down by open-source vs closed source, and SQL vs NoSQL.
The database market, in my opinion, follows a long-tail distribution:

A few databases dominate the majority of use cases, while hundreds of databases exist for niche use cases. This is because choosing between databases is about deciding between what will get the job done and what will get the job done best. So, a popular database like PostgreSQL (or insert Oracle/MySQL/etc) can complete the needs for most SQL-based projects. But, there might be 20 specific databases that complete very specific tasks better than other databases. (Check out database rankings to see what I’m talking about.)
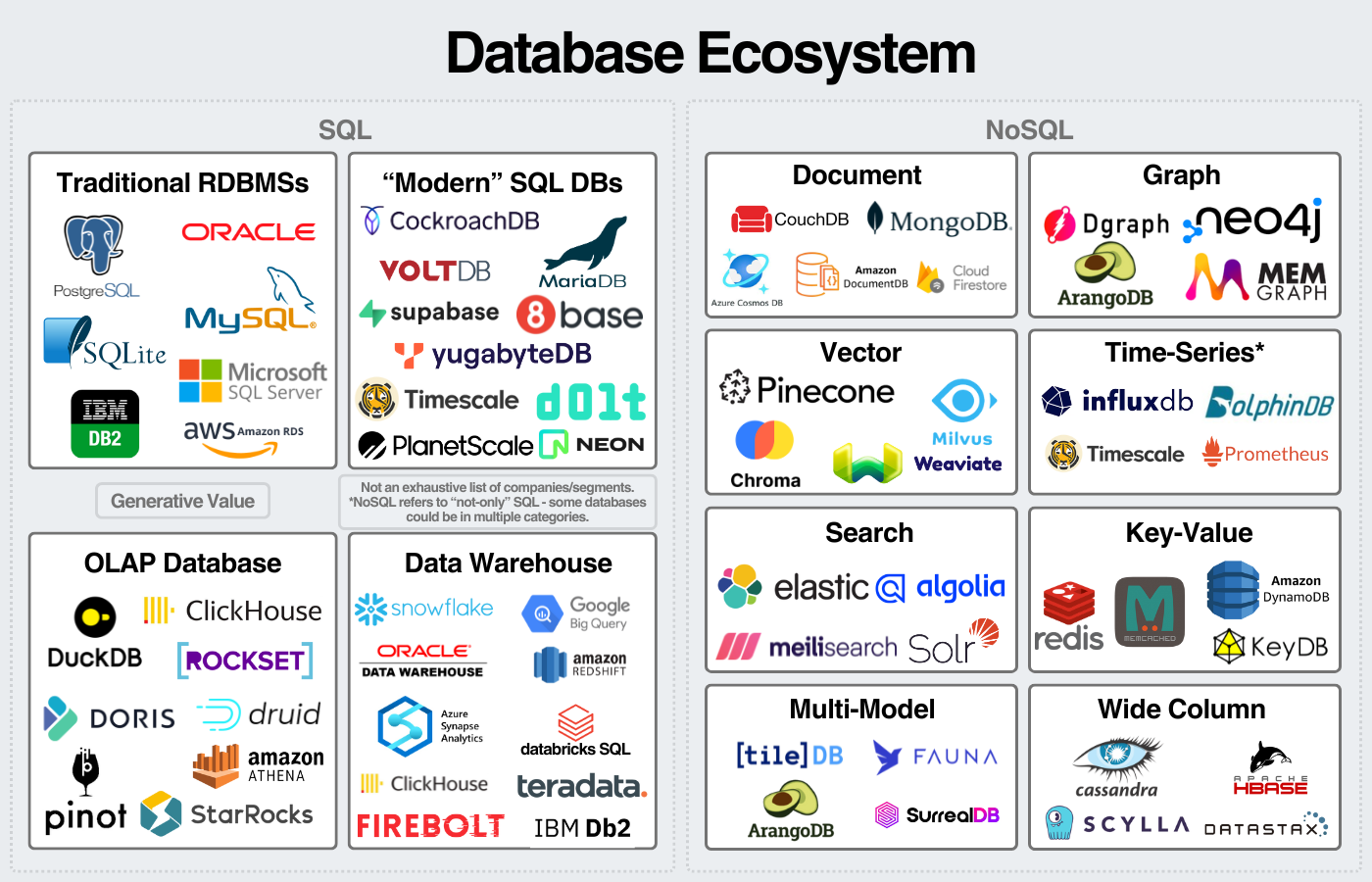
This leads to a few very large database companies and a long tail of niche databases for specific tasks. Databases are such a large market that they justify the long-tail of databases to exist. We can see some of the sectors and companies here:
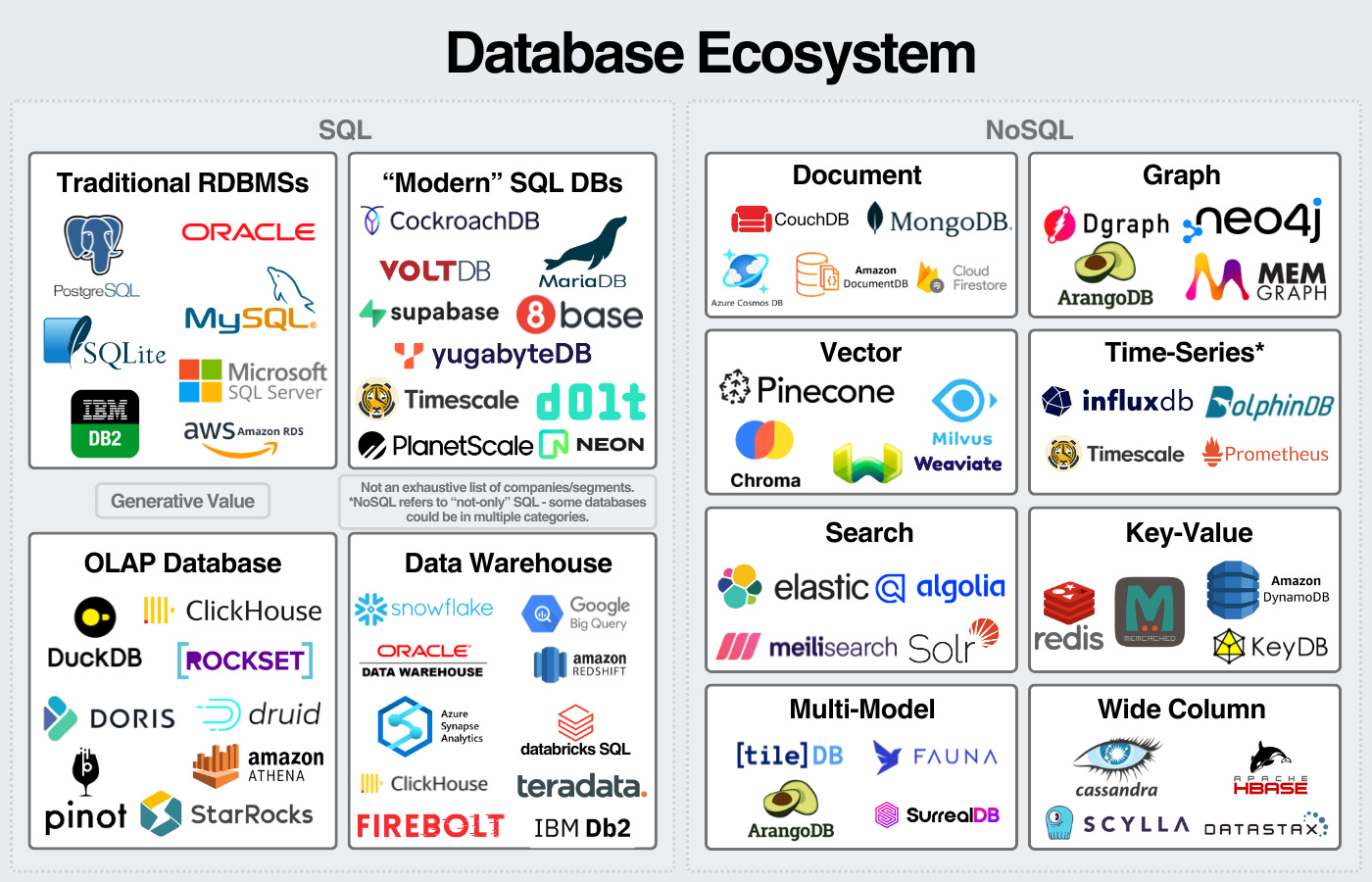
This long-tail of databases continues to extend as the barrier to software development lowers.
2. A History of Databases
I’m going to shorten this section, as I think my previous articles have covered the history of the data space well.
We can essentially break down the history of databases into the rise of the SQL database, the rise of unstructured databases/the cloud, and the modern era of databases.
1. The SQL database invention.
(Worthwhile video by Asianometry here.)
The first database was invented in 1961 at GE and included a data model, description language, and manipulation language (store, retrieve, modify, delete). At this time, software was bundled with hardware and essentially given away for free to interact with the hardware.
Edgar Todd published two important papers in 1969 and 1970, the latter of which became known as one of the defining papers in databases: “A Relational Model of Data for Large Shared Data Banks.” Shortly after, two IBM employees invented the SQL programming language for querying large data banks.
In 1979, Oracle released the first SQL-based relational database management system. IBM DB2 followed shortly, and Microsoft SQL Server later in the 80s. Over the next 10-20 years, the industry would consolidate, with these three companies leading the database market.
2. The rise of unstructured data and the cloud.
The combination of the Internet, the cloud, and mobile created what Charlie Munger would describe as “Lollapalooza effects.” In my opinion, the incredible growth of the technology industry over the last twenty years was driven by the fact that three of the most important trends in history converged at the same time.
The database market was a key beneficiary of this convergence.
The internet led to the proliferation of unstructured data; mobile contributed to the rise of applications needing databases, and the cloud provided a disruptive model for building technology. Combined, they led to the rise of cloud-based data companies like Snowflake, Databricks, and MongoDB (as well as new data offerings from AWS and GCP).
A primary beneficiary of unstructured data was the NoSQL database, originating sometime in the late 1990s. Apache Lucene (a search database) was released in 1999. Popular NoSQL databases like MongoDB, Neo4j, Redis, and DynamoDB were released from 2007-2012
Interestingly, the incumbents fared well in the cloud data market. Microsoft, Oracle, and IBM still have multi-billion dollar product lines from databases. It’s a testament to the stickiness of databases; Oracle has just recently allowed Oracle databases to be hosted in other clouds, and they are still the most used relational databases in the world.
Another important trend was the “diversification” of databases - meaning many databases were released in the 2010s to solve increasingly niche tasks. As the database market grew, it justified more and more niches; we still see many databases released every year.
3. The rise of AI databases?
The relationship between data and AI has been well-marketed. For LLMs, the vector database has been at the heart of this relationship.
Some background on vector databases (put as simply as I can):
Vector databases have the ability to store unstructured data as numeric values. Vector embeddings are created from these values, and mapped based on their meaning. Applications can then pull data based on how close mappings are to each other. See below:

The key feature here for LLMs is the ability to understand a language’s “meaning” and not just its definition. So, an LLM can understand that “wolf” or “puppy” is semantically similar to “dog.”
See popular open-source vector databases here:
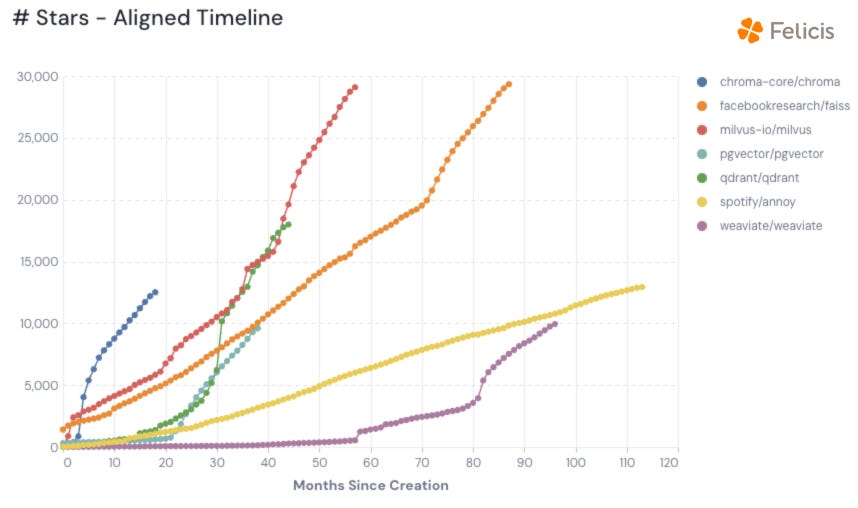
Additionally, we have hardware-based data products like VAST Data, which was recently valued at over $9B.
This is to say that data is receiving an incredible amount of 1. focus from technologists and 2. attention from investors for potential investments. This much capital and brainpower focused on an area inevitably leads to some exciting innovations.
On to technology.
3. Overview of Database Technology
I’ve decided to divide this section into two parts: the core technology behind databases and a quick list of the different types of databases. (I originally wrote out a few paragraphs for each type of database, but I got bored reading it back, so I have no doubt readers would, too.)
By the way, Technically has an excellent beginner’s guide here that’s worth reading. I like his breakdown of databases here:

When choosing databases, we have to ask ourselves two questions:
- What do we need to do with the data?
- What does the data look like?
Many databases are available for each use case, so the final decision typically depends on what the developers are used to working with and what cloud environment the application is hosted in.
The above graphic highlights the three main use cases. Databases behind applications are transactional databases. Databases for analytics are analytical databases. Other databases, like search databases or vector databases, fall into a third category for more specific tasks.
Then, we have SQL databases for structured databases and NoSQL databases for any database that’s not specifically a SQL database.
We can visualize the database landscape here:
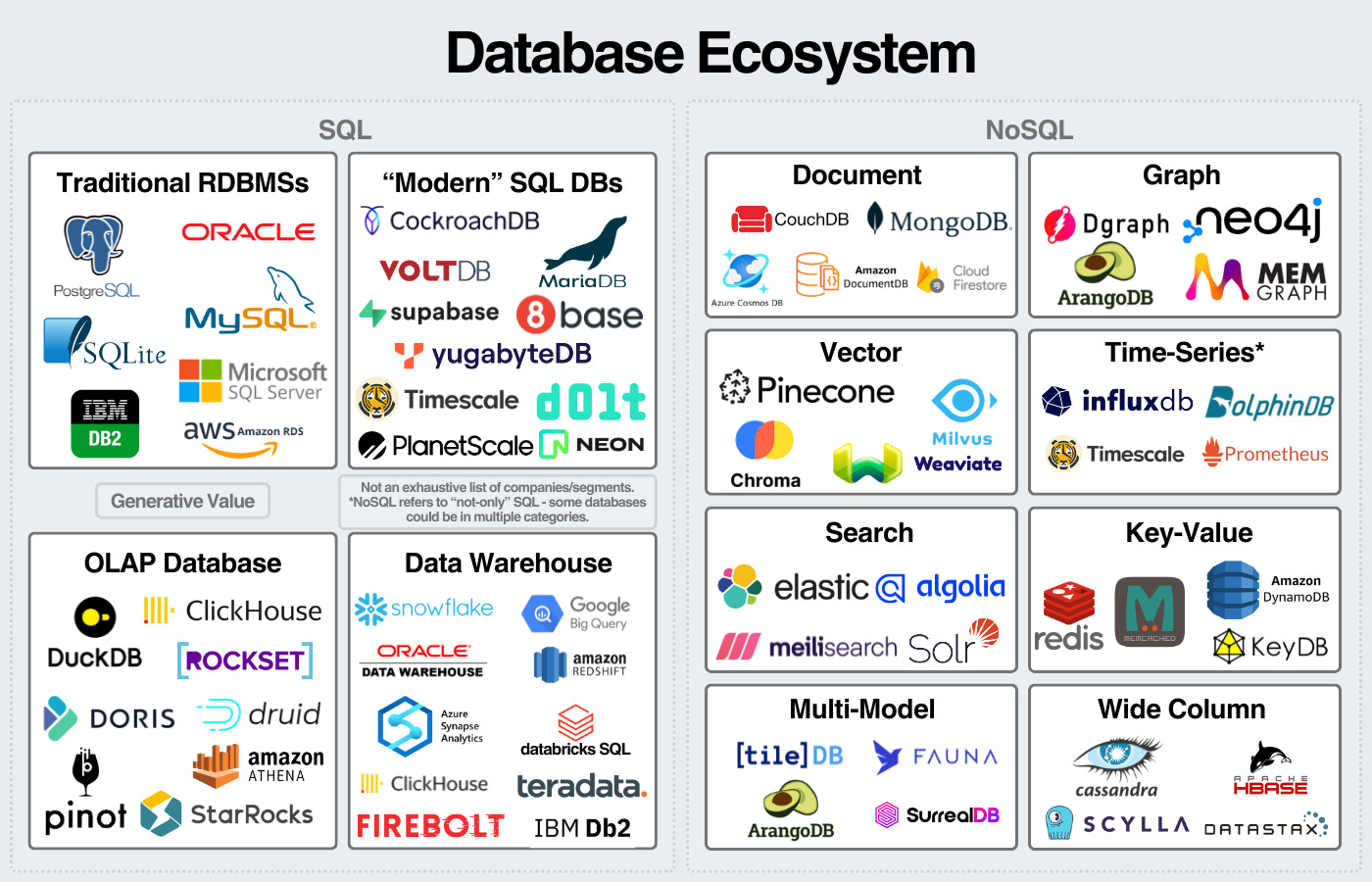
An important disclaimer: the names of the boxes are flexible. I view this as a flexible mental model to break down the industry. Some databases can be used for SQL and NoSQL workloads. Some databases fall into multiple categories. I left out some database categories and companies to keep the graphic somewhat digestible.
List of Database Types
SQL Databases
- Relational database management systems (RDBMSs) - Manage SQL databases and are the largest database category in the market. Oracle, MSFT SQL Server, MySQL, and PostgreSQL are popular offerings.
- NewSQL DBs or “Modern” SQL DBs as I’m calling them - This term is somewhat nebulous and I’m referring to the new SQL databases released in the 2010s and 2020s. Traditionally, NewSQL has referred to relational databases designed to run distributed across many virtual machines with the goal of having higher reliability. MariaDB, CockroachDB, YugabyteDB, and TiDB are four popular examples.
- Analytical DBs - Databases designed for rapid analytics. Clickhouse, Rockset, and DuckDB are popular examples.
- Data Warehouses - Databases design to store and analyze massive amounts of data. See my data warehouse article for more context.
Not-Only SQL (NoSQL) Databases
- Document DBs - Most popular NoSQL database storing unstructured data as key-value pairs, storing those in documents, and storing those documents in collections. They provide a way to add structure to unstructured data. Popular examples include MongoDB, Azure CosmosDB, and Amazon DocumentDB.
- Graph DBs - Store data as relational graphs, good for strong relational data like social media graphs. Popular databases are Neo4j, Dgraph, and memgraph.
- Vector DBs - Store data as embeddings for closest-match searches. Popular databases include Pinecone, Milvus, Weaviate, and Chroma.
- Time-Series DBs - Store time-series data like weather data. Popular examples are Timescale and InfluxDB.
- Search DBs - Databases for search functionality and indexing/retrieving information. Popular DBs include Elasticsearch, meilisearch, and Algolia.
- Key-Value DBs - Simple DB storing key-value pairs, typically used for caching. Redis is the most popular offering.
- Multi-Model DBs - Combine the functionality of different databases in the back end and allow one pane of glass for querying. Popular DBs include ArangoDB, FaunaDB, and SurrealDB.
- Wide Column DBs - Store data as keys and rows of data associated with keys. Popular DBs include Cassandra, Scylla, and Datastax.
Again, the most important point here is that nuance exists in the database market; many of these databases can be used for the same tasks.
4. Database Statistics
We don’t have many public references for the scale of database markets (we only have one public pure-play database company and that’s MongoDB). So off to alternative data we go!
DB-Engines does a great job tracking database popularity, and we can see that here:
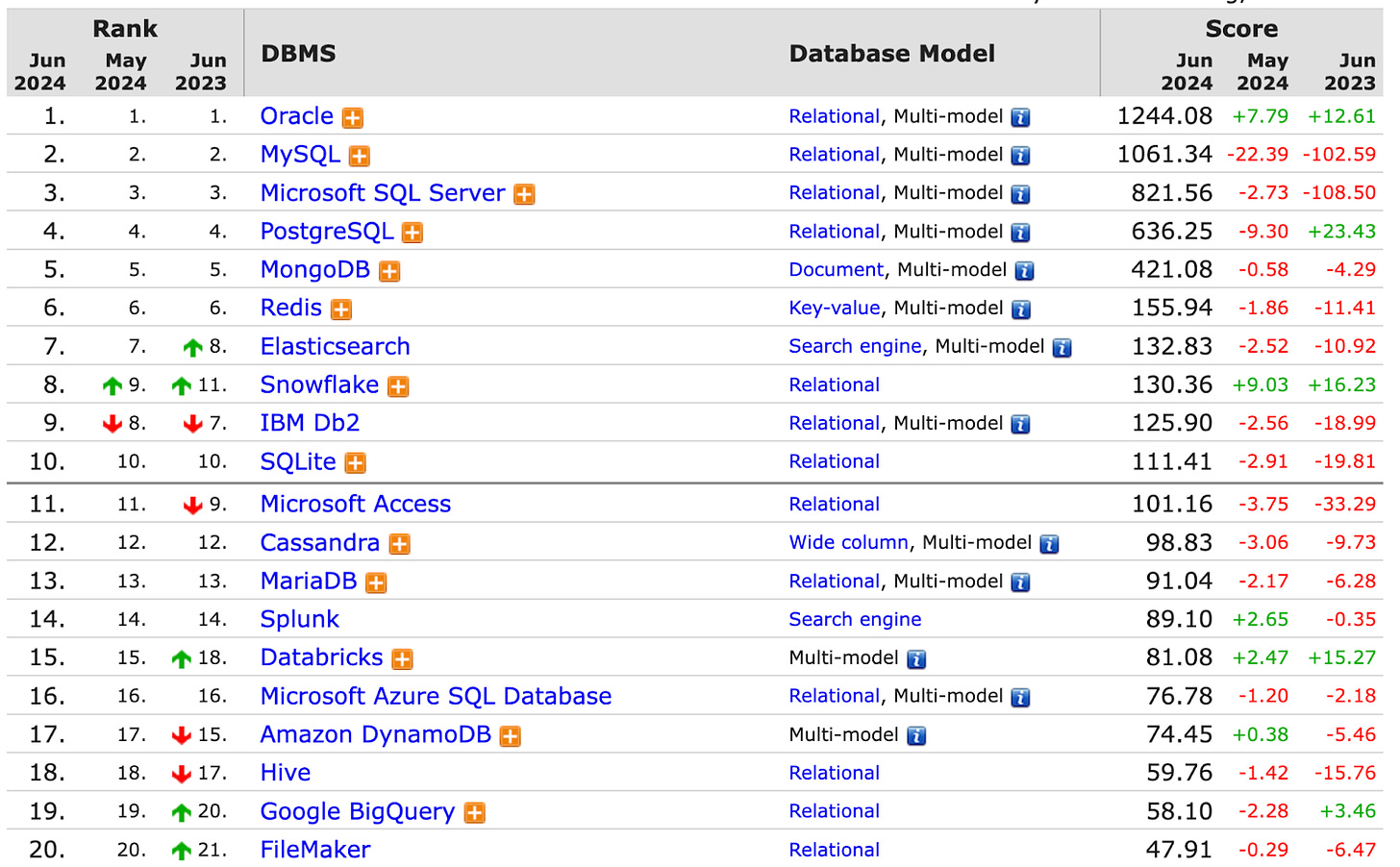
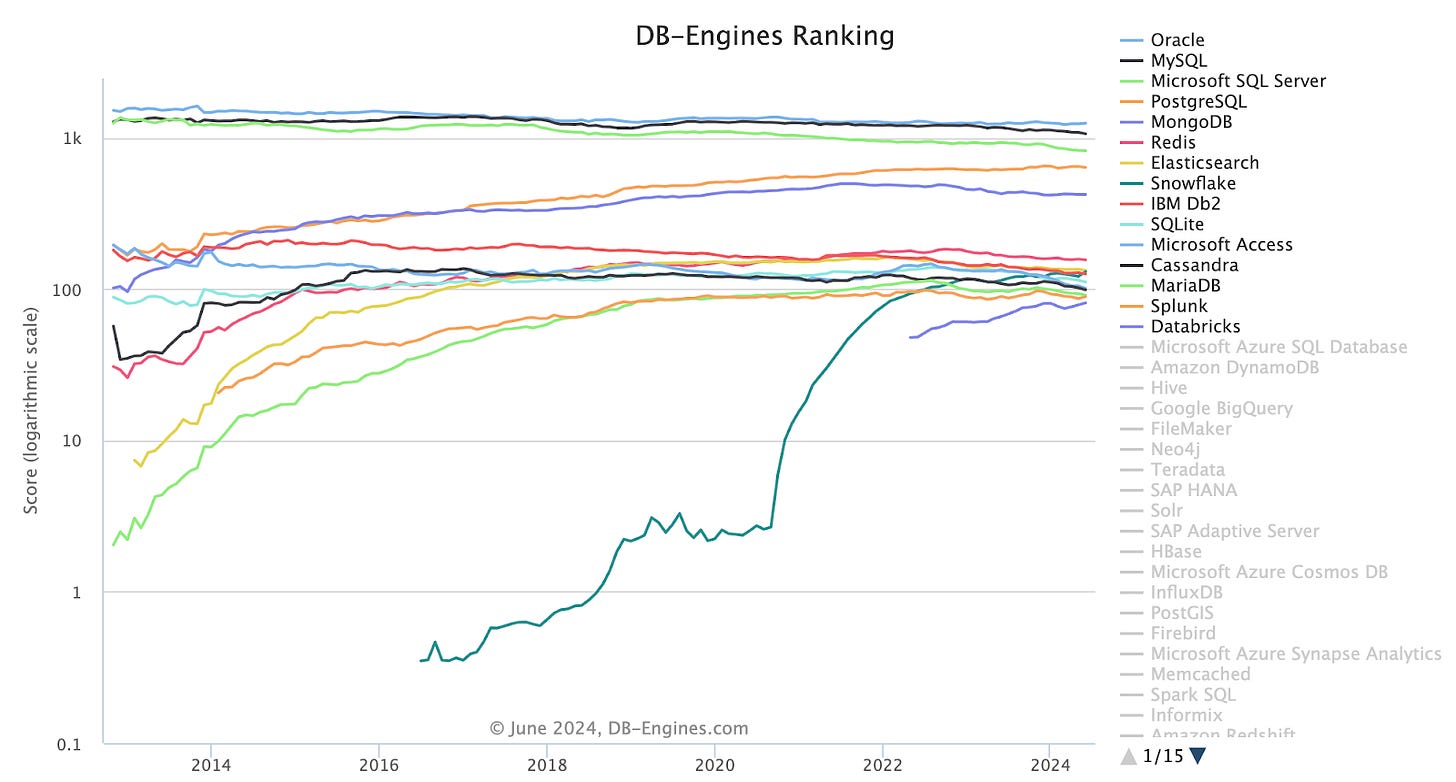
Comparing that to growth over time again highlights the stickiness of databases:
The other good metric to get a feel for developer adoption is open-souce trends on GitHub. I pulled some of the most popular open-source databases over time on GitHub here:
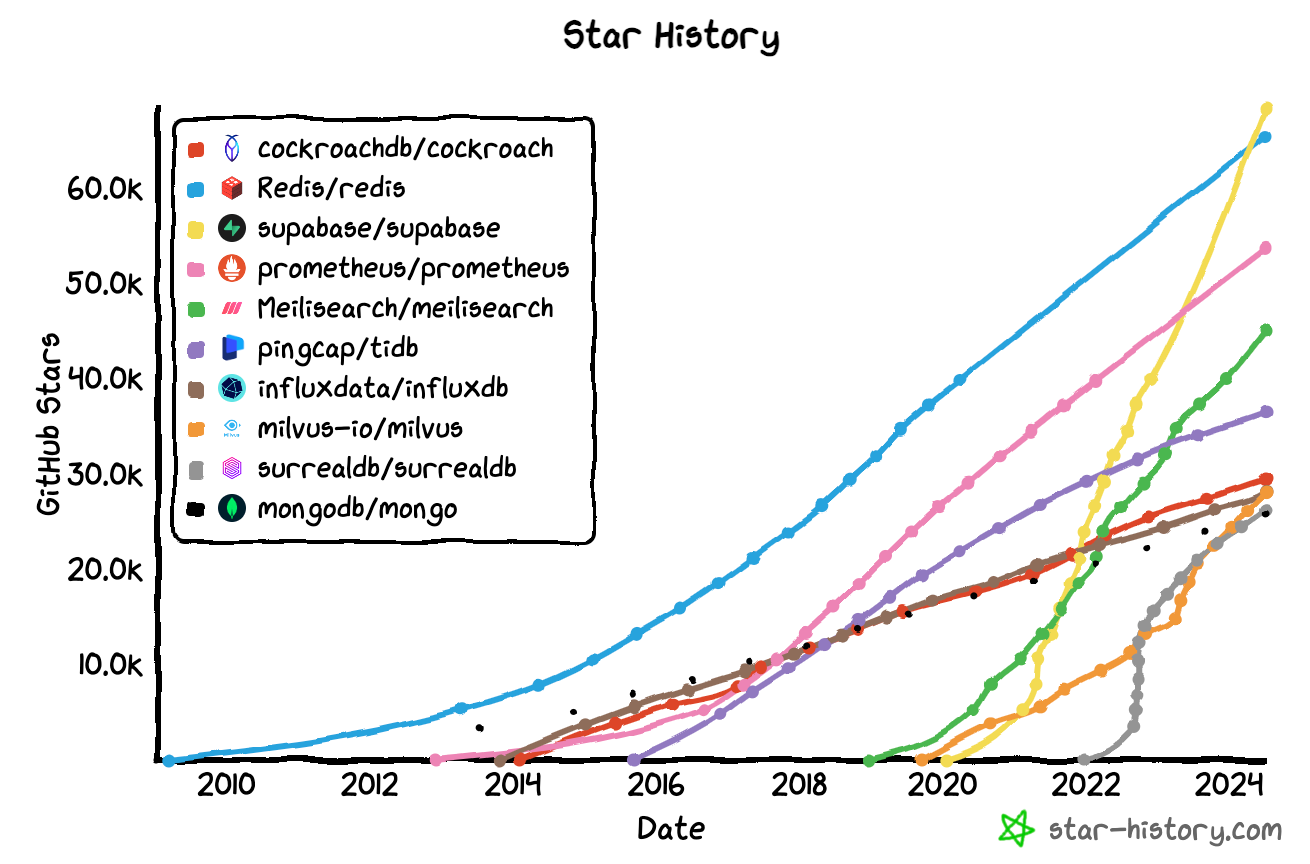
So this data essentially tells us that relational databases continue to be king, databases are clearly sticky, open-source databases continue to grow in adoption, and there’s a massive amount of competition in the space.
Public Company Data
Finally, despite not having much public data, we can gather some information by examining pure-play data companies as a whole (Note: only Mongo is directly a database company here).
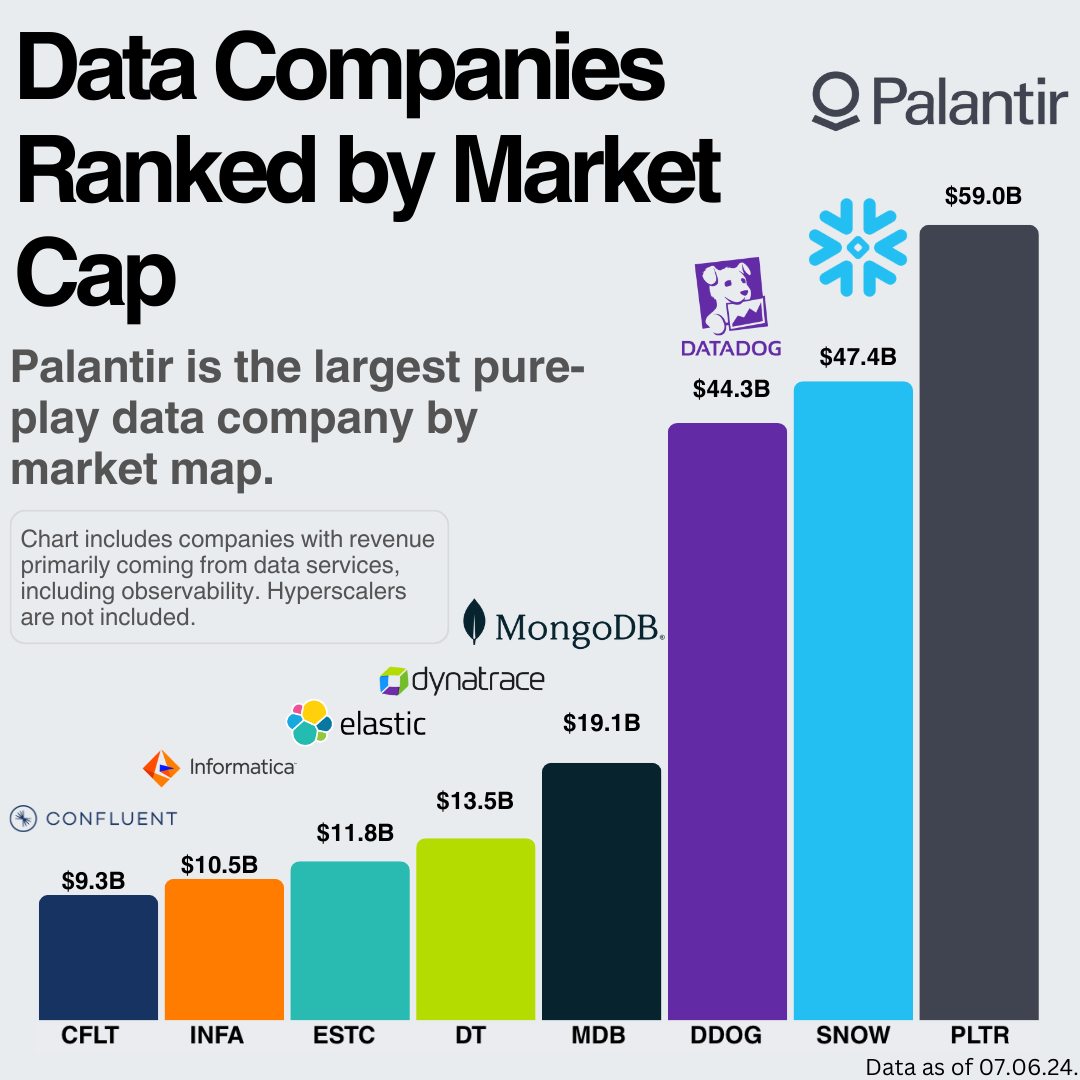
While only a few of these companies are database companies, we can get an idea of market size via Snowflake, MongoDB, and Elastic. For reference, Oracle’s market cap is $383B with $14B in revenue, although this also comes from business applications and cloud infra. We can also look at relative valuations in the space using PSG (I prefer growth-adjusted valuation ratios).
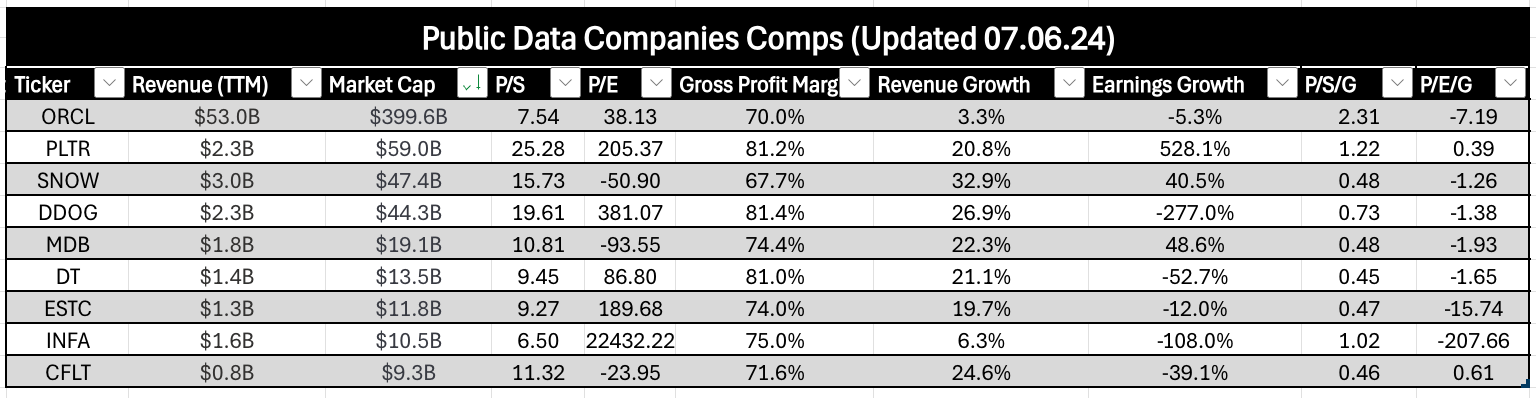
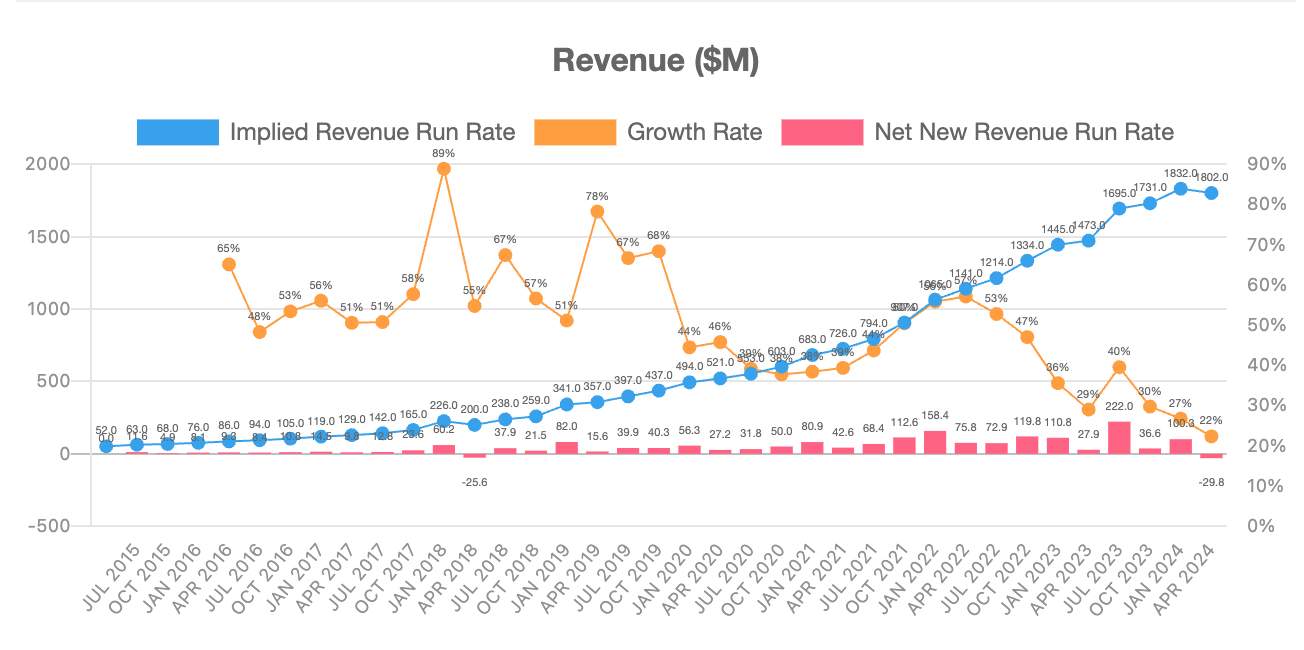
If we look at an individual company like MongoDB, we see data that’s playing out across the SaaS landscape (see latest Clouded Judgement article). Companies are still growing quickly, but that growth is slowing.
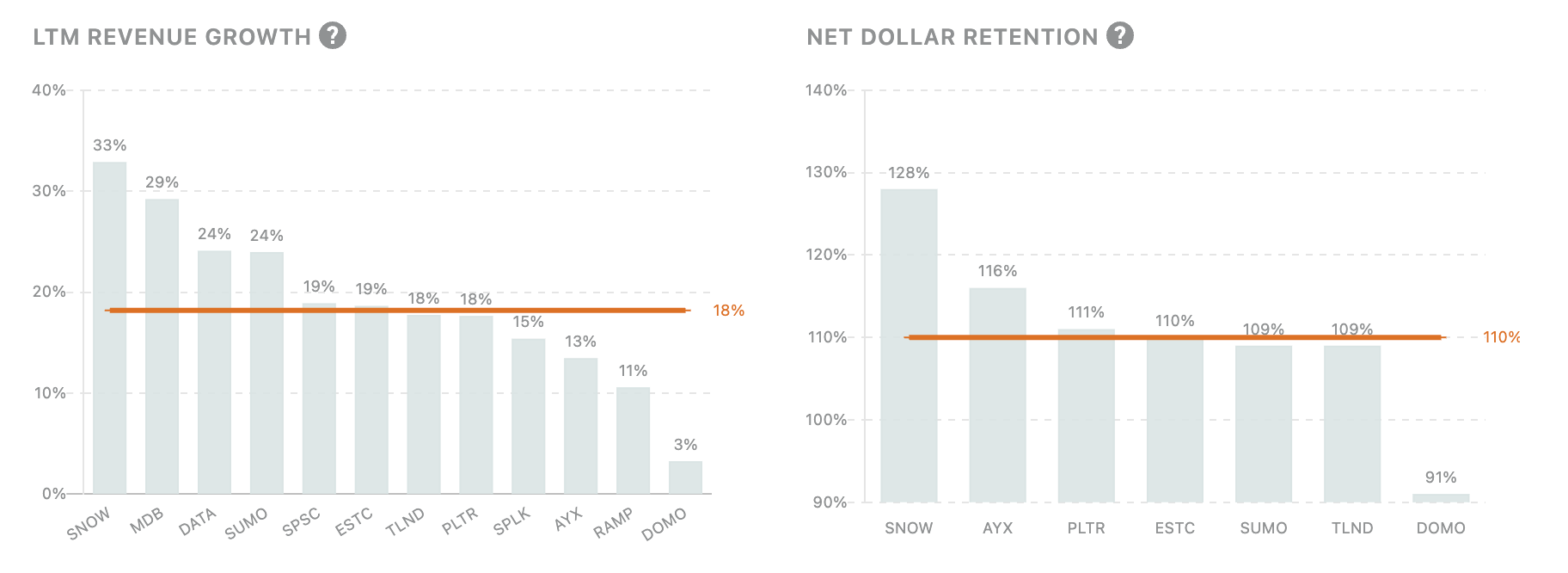
5. Public Comps Data
Across public data companies we track, we can see LTM Revenue Growth, NRR, EV/Gross Profit, and EV/ARR among other metrics:
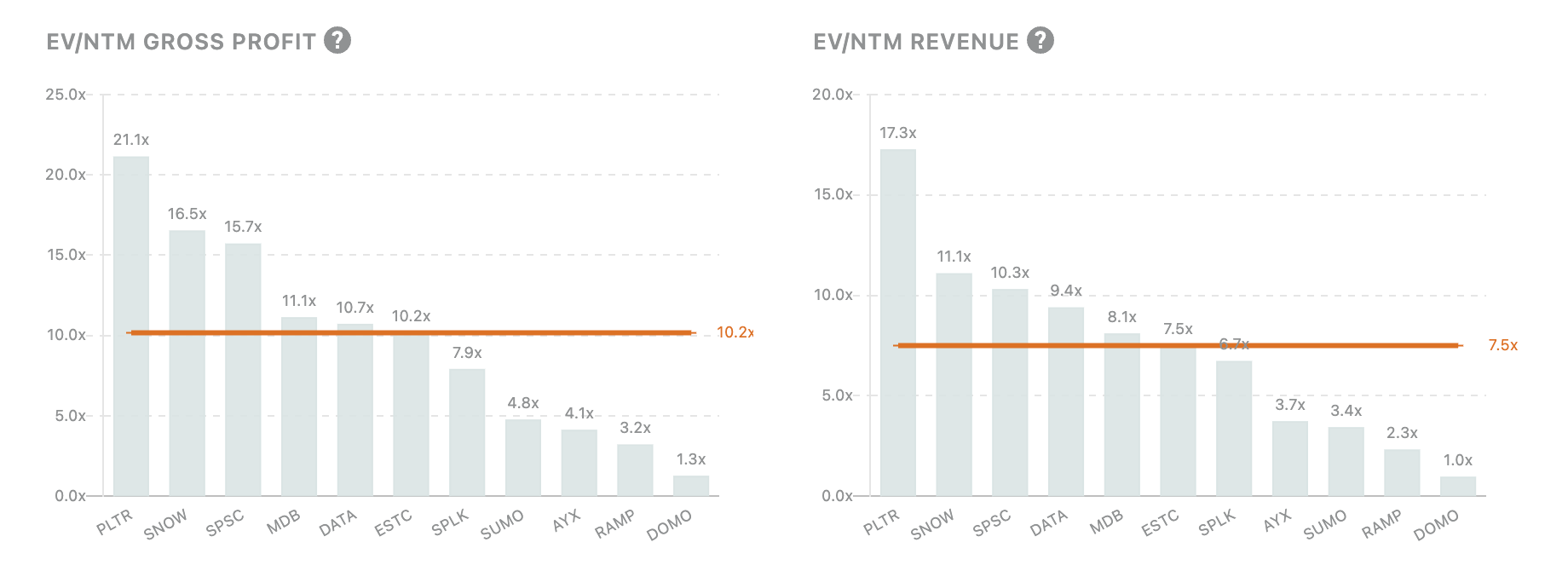
For individual companies, we can see public data filings and compare them to other comparable companies. Taking SNOW for example:
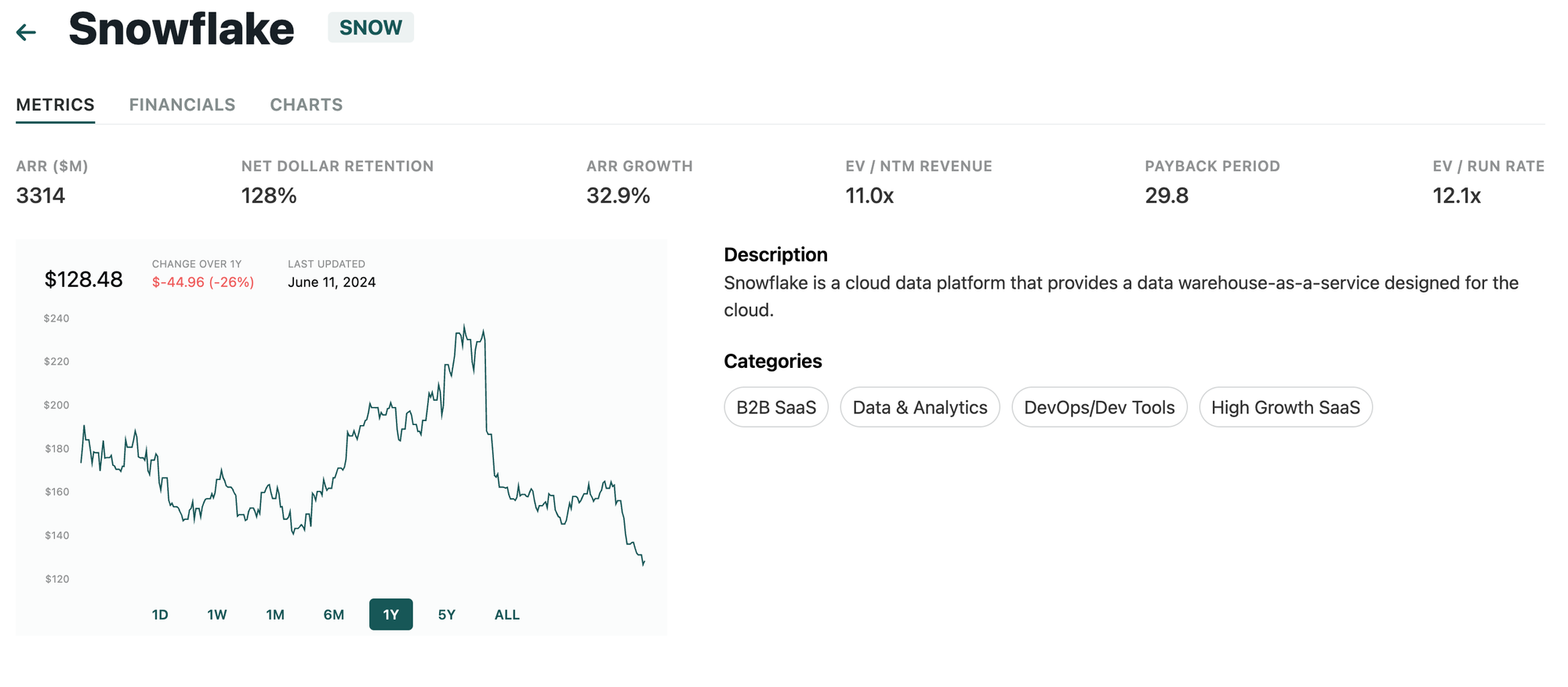
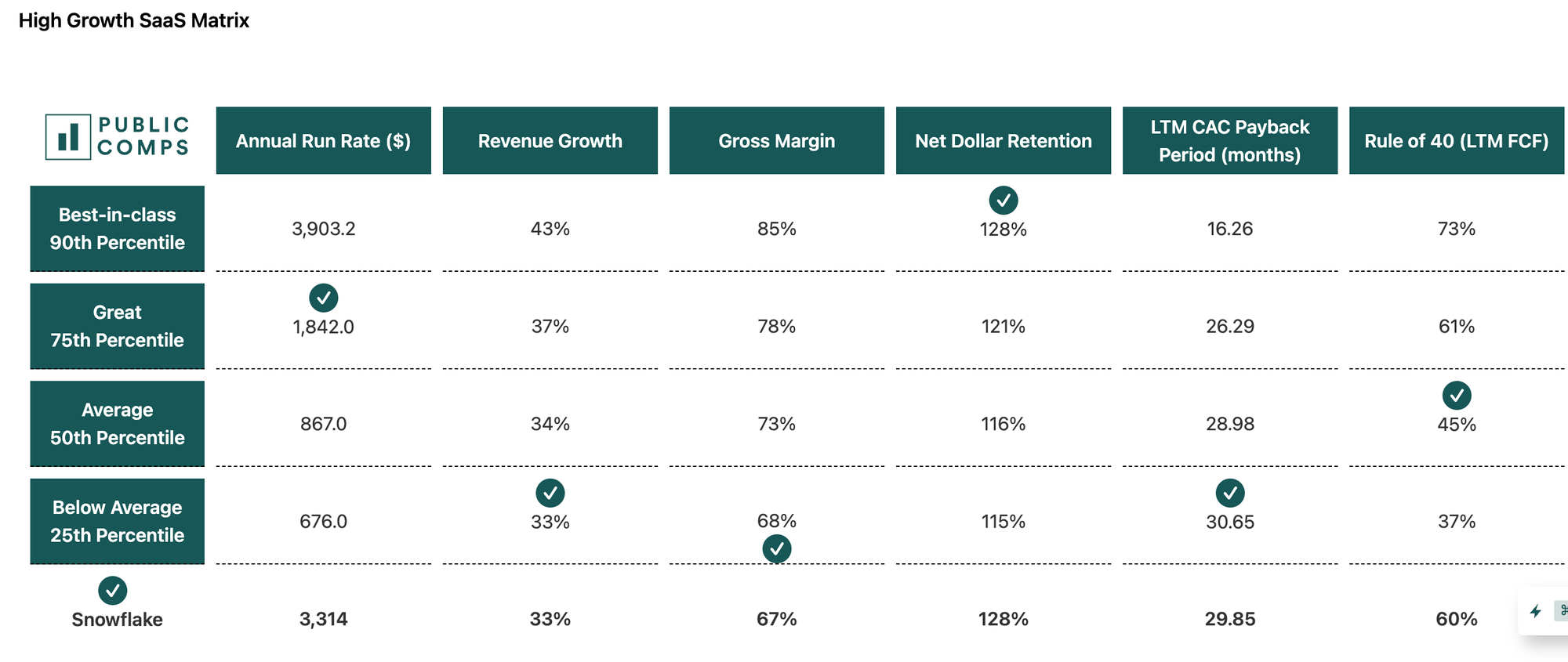
As always, thanks for reading!
Disclaimer: The information contained in this article is not investment advice and should not be used as such. Investors should do their own due diligence before investing in any securities discussed in this article. While I strive for accuracy, I can’t guarantee the accuracy or reliability of this information. This article is based on my opinions and should be considered as such, not a point of fact. Views expressed are solely my own, not those of Public Comps or other employers.